True campaign velocity is defined by how cleanly you recover from the inevitable, minor failures in large-scale content batches, not how fast you launch them. When a bulk content job stalls halfway through, most teams default to "nuke and pave": deleting everything and restarting the entire upload. It is a costly, time-sucking reflex that kills momentum and creates unnecessary coordination debt.
We get it. You have spent hours aligning CSVs, media assets, and captions, only to watch a progress bar stop dead. That sinking feeling of manual cleanup or mass-re-uploading is the silent killer of content strategy. It turns a simple scheduling task into a frantic, late-night project. You do not need to rebuild your entire calendar because three rows failed; you need a surgical, row-level retry process that keeps your campaign on schedule.
The operating problem this solves

The awkward truth is that your biggest platform bottleneck is not the API or the media size. It is the "all-or-nothing" recovery workflow that forces you to treat 1,000 successful posts as "contaminated" because of five failed ones. Every time your team manually deletes and re-uploads a batch, you are essentially paying a "coordination tax" in time, sanity, and potential scheduling errors.
This manual thrash becomes unsustainable when you are managing dozens of brand profiles across multiple regions. If you are still relying on a spreadsheet that has become a crime scene of Failed and Retrying notes, you are working against your own infrastructure.
We built the retry logic at Mydrop because we have felt the pain of watching a long-running job die at 99%. Here is how the math of recovery actually looks when you stop nuking the entire job:
| Metric | Manual "Nuke and Pave" | Row-Level Retry |
|---|---|---|
| Initial Cleanup | 30-45 minutes to audit and delete | 0 minutes (system handles) |
| Asset Preparation | Re-verifying 500 rows for errors | 2 minutes (isolate 5 errors) |
| Upload/Processing | 45-60 minutes full re-import | < 1 minute (delta only) |
| Total TTR | 120+ minutes | ~2 minutes |
Operator rule: If your recovery process takes longer than the actual campaign planning, you are not fixing the failure; you are just repeating the work.
Most enterprise teams overbuild their recovery path by writing custom scripts to parse error logs or attempting to track "failed" status in a shared master sheet. These are fragile stop-gaps. The system you actually need is one that treats every content row as an atomic unit of work. By isolating the failures and resolving only the delta, you shift from playing "catch-up" to maintaining a steady, reliable rhythm. This is the difference between a team that is constantly putting out fires and one that treats minor job hiccups as a two-minute administrative checkbox.
The minimum system that works

The secret to reliable scale is treating your content queue like a distributed transaction, not a static file upload. If your system treats a thousand posts as one giant, indivisible unit, it is practically begging for a disaster at the 99% mark.
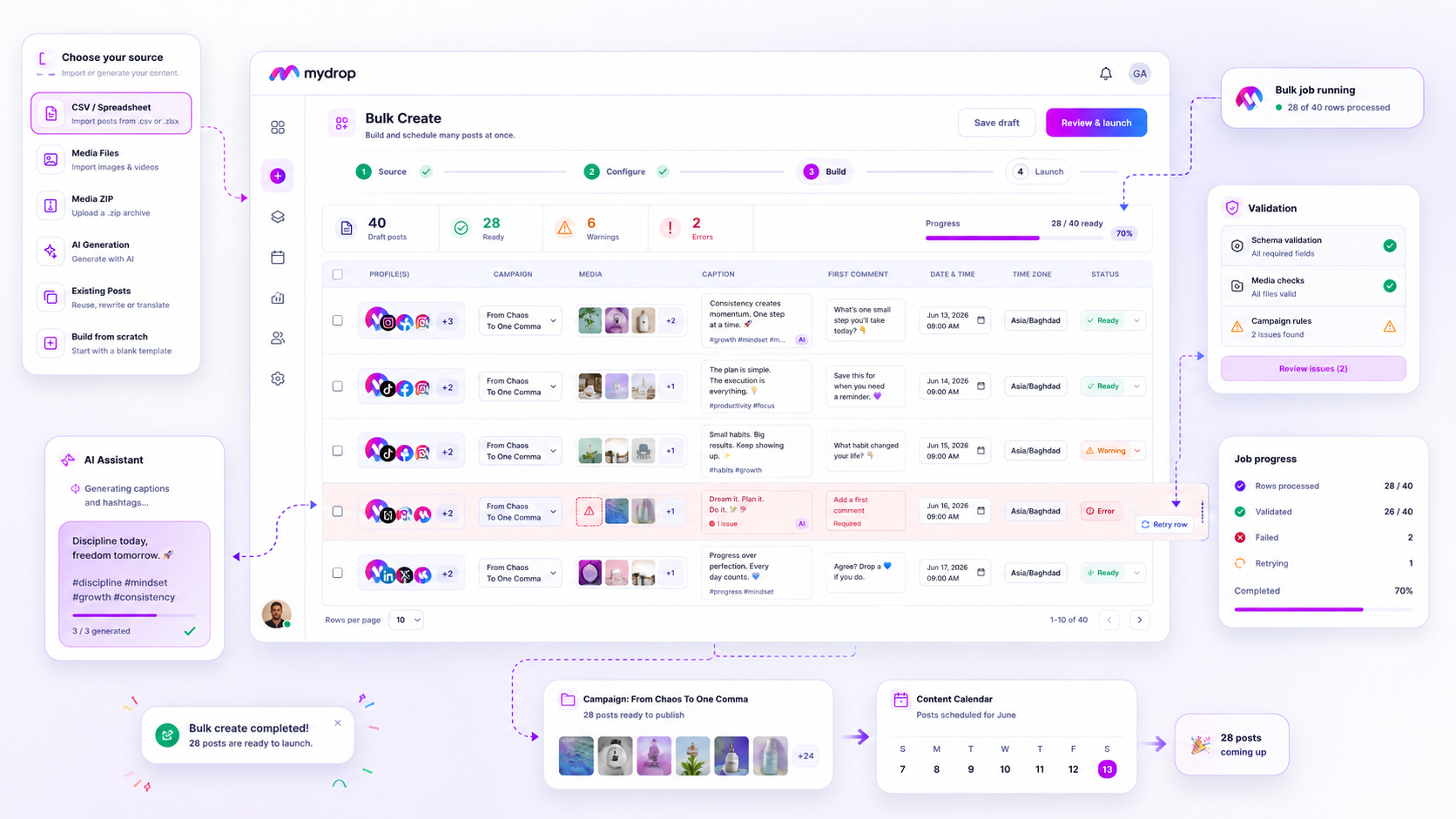
In our experience, teams that stop fighting the "all-or-nothing" cycle are the ones who break their campaigns down into atomic, retryable rows. A robust system doesn't care if the job is 5 posts or 5,000; it treats every row as a standalone task with its own pending, done, or failed state. When a batch hits a snag-like a transient API timeout or a momentary blip in asset hosting-you aren't forced to delete the progress you already made. You simply clear the cache for those five problematic rows and hit retry.
At Mydrop, we built our bulk engine around this principle because we have felt that same frustration of watching a massive upload die just before completion. It transforms a high-stakes emergency into a routine five-minute cleanup.
Where teams overbuild the process
Here is where teams usually get stuck: they try to engineer their way out of this problem with custom scripts, complex Zapier chains, or bloated spreadsheet macros. They treat error tracking like a developer project, often creating more coordination debt than the original manual effort.
If you are spending more time managing your "error-tracking-spreadsheet" than you are creating content, you have built the wrong tool. Custom solutions often lack the persistent, real-time feedback loops required for true enterprise agility. They might tell you a job failed, but they don't give you the surgical control to resolve a single row without disturbing the rest of the calendar.
The real goal isn't just to catch errors; it is to keep the campaign running.
Cost of Recovery: Manual vs. Automated Row-Retry
| Metric | Manual "Nuke and Pave" | Mydrop Row-Level Retry |
|---|---|---|
| Primary Workflow | Delete all, fix CSV, re-upload | Identify error, fix row, hit Retry |
| System Interaction | Full job wipe, re-validation | Delta-update only |
| Time to Resolution | 120+ minutes (typical for large batches) | 2 minutes (typical) |
| Risk of Regression | High (duplicate posts, lost history) | Low (atomic row state persists) |
| Stakeholder Visibility | Opaque (job status "Failed") | Clear (row-level success/error stats) |
Calculations based on a sample 500-post campaign with a 1% failure rate. Manual recovery assumes full re-validation and re-scheduling of all posts, while row-level retry assumes immediate resolution of the 5 delta items.
Most teams do not have a content-creation problem. They have a coordination bottleneck. When you stop treating bulk publishing as a "launch event" and start treating it as a managed, persistent data stream, you remove the fear of the progress bar. You aren't just saving time; you are protecting your team's sanity by ensuring that the only work you ever have to repeat is the work that actually needs fixing.
How to run the cadence
The biggest mistake teams make is treating a failed bulk job as a disaster that requires an all-hands meeting. Instead, treat it like a standard exception in your morning sync. If you are managing a high-volume calendar, your team needs a standing "Check-Resolve-Retry" habit that takes less than five minutes of actual human effort.
Here is the operational rhythm for your content lead:
- The Morning Triage: Check the Bulk Jobs Listener. If a job shows a
failedorpartialstate, don't panic. Open the job to see theitemssubcollection. - The Filtered View: Immediately filter for
failedrow statuses. You will almost always find that the failure is isolated to a handful of items-a corrupted image file, a missing tag, or a typo in a required field. - The Correction: Update the specific row content directly within the job UI. You do not need to re-import the entire source file.
- The Surgical Trigger: Hit the Retry action. This tells the worker to pick up only those specific rows, re-validate them, and push them to the platform.
Decision check: Never "delete and restart" until you have exhausted the row-level retry path. If you delete a bulk job, you are manually performing the work the system is designed to handle for you.
The proof that the habit is working
When you move from manual "nuke and pave" to surgical retry, the change in your team’s stress levels is measurable. It isn't just about saving time; it's about protecting the morale of the people who have to build these campaigns.
Cost of Recovery: Manual vs. Automated Row-Retry
| Metric | Manual Rebuild ("Nuke and Pave") | Mydrop Row-Level Retry |
|---|---|---|
| Initial Setup Time | 60 minutes | 60 minutes |
| Error Identification | 15 minutes (manual scanning) | < 1 minute (UI flag) |
| Correction Workflow | 45 minutes (re-import & re-validate) | 2 minutes (inline edit) |
| Platform Re-upload | 30 minutes | 1 minute (delta only) |
| Total TTR | 150+ minutes | ~64 minutes |
Note: TTR = Time to Resolution. This example assumes a 500-post campaign with 5 failed rows.
Beyond the clock, you start seeing the "confidence dividend." When your team knows that a minor error won't force them to redo hours of work, they are much more willing to experiment with larger, more ambitious content batches. They stop fearing the "upload button" because the safety net is built into the job itself.
Conclusion
At the end of the day, your campaign velocity isn't about how fast you can push an upload button; it’s about how gracefully you handle the small, inevitable friction points. True scale requires a system that allows you to be precise when things go wrong.
Stop treating your content calendar as a fragile object that breaks under pressure. By isolating failures and retrying only the delta, you stop managing spreadsheets and start managing the actual content strategy. If you’re ready to stop the "rebuild-everything" cycle, start by identifying the next job that stalls and simply hitting "retry" instead of "delete." It is the most boring, and effective, move you can make for your team’s peace of mind.