"Publishing failed." It is the two words that ruin a social media manager’s day, turning a well-oiled launch into a chaotic scramble. But here is the hard truth: in agency-scale operations, preventing every error is impossible. Reliability isn't about perfection; it is about the speed and transparency of your resolution system. If you manage dozens of channels, you know this is not a rare annoyance-it is a predictable cost of operation. When platform APIs have a mind of their own, the win is how quickly you can surface the issue, identify the root cause, and fix it before your clients notice. If your tool treats these warnings as silent background noise, you are losing more than just time; you are losing trust.
What the best tools need to handle

When you are managing accounts for multiple clients, you do not have the luxury of playing detective. You need a system that acts as an early warning bridge, not a black box.
Here is the reality of the situation: platforms change their rules, tokens expire, and APIs get grumpy. The best tools do not hide these facts; they put them front and center.
Operator rule: If you cannot tell in thirty seconds why a post failed, your tool is failing you.
You need a platform that moves beyond generic "failed" messages. You need context. Did the token expire, or was it a rate limit issue? Is the media format unsupported, or is the platform just having a bad day?
The Reliability Diagnostic
| Failure Type | Signal to Look For | Proactive Action |
|---|---|---|
| Auth Drift | Invalid token/session | Auto-refresh or explicit alert |
| Constraint Conflict | Aspect ratio/file size error | Pre-flight validation scan |
| API Throttle | Too many requests/rate limit | Dynamic queue backoff |
| Platform Outage | 500-range error/timeout | Graceful retry and notification |
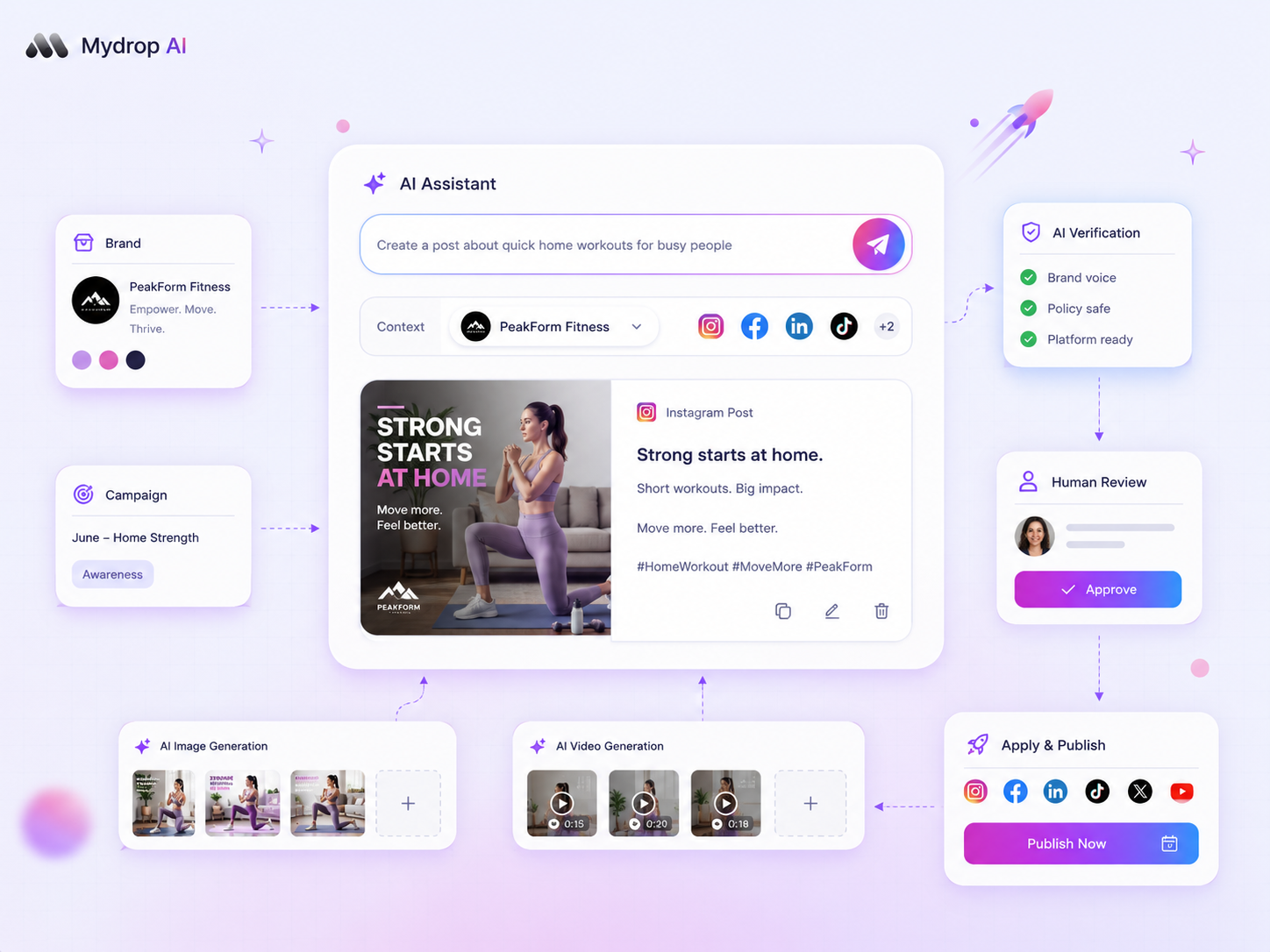
At Mydrop, we have found that surfaced warnings are significantly better than silent errors. This is why we designed our status dashboard to distinguish between waiting, warning, and failed states immediately. Instead of waiting for a client to ping you about a missing post, you should already be halfway through the fix because your dashboard highlighted the conflict the moment it occurred.
If your current workflow requires you to manually check every post after the fact, you are carrying unnecessary coordination debt. The best tools handle the heavy lifting by flagging these issues during the scheduling phase. A tool that stops you from scheduling a video that exceeds a specific platform limit is not just a convenience-it is an essential guardrail that saves your team from a weekend of damage control.
Ultimately, the goal is to shift from reactive firefighting to proactive management. When you stop chasing ghosts and start managing exceptions, your team can focus on what actually moves the needle for your clients: the strategy, the creative, and the engagement, not the mechanics of a failed upload.
Where basic tools start to break

Basic tools treat publishing as a one-way street. You send a file, the tool hits an API endpoint, and you hope for the best. When that post hits a snag, these tools often stay quiet or bury the failure in a sub-menu you rarely check.
The real problem for agency teams is the gap between what your tool says and what is actually live on the channel. Basic platforms might report a successful request, but the channel itself rejected the asset due to a hidden constraint. Suddenly, you have a client asking why their Reel never showed up, and your team is stuck digging through platform logs.
It gets worse when you manage dozens of brand profiles. When you scale, these small failures compound. If a tool fails to warn you about a pending token expiration or an aspect ratio mismatch, you are not managing social; you are babysitting manual retries.
Most tools also struggle to distinguish between a temporary API hiccup and a permanent blocker. They treat every error as a generic failure. An agency operator needs to know: Is this a transient rate limit I should just retry, or is it a fundamental credential issue that requires me to reach out to the client? If your tool leaves you guessing, it is actually adding to your workload, not reducing it.
The buying criteria that matter
When evaluating a tool for your agency, stop asking if it can schedule posts. Every tool does that. Start asking how it handles the friction of publishing to ten different platforms simultaneously.
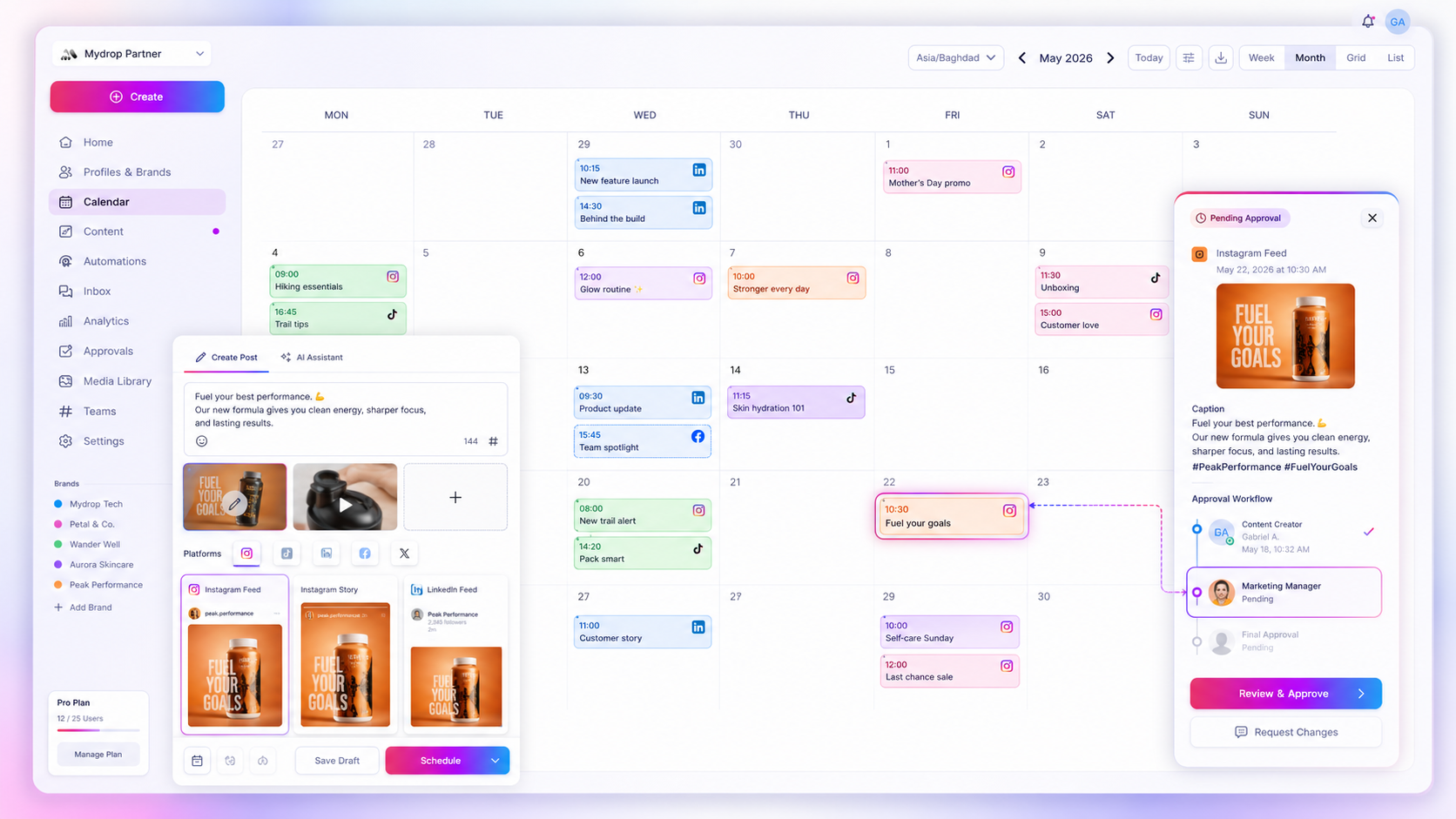
You need a system that treats status changes as actionable data. If an Instagram upload hits a daily quota or a thread fails to push to X, your team should know instantly, not three hours later when the engagement metrics show zero.
The most important differentiator is transparency. You want a tool that gives you a clear, honest view of the status for every single platform, even if the news is bad. If you cannot see the difference between a post waiting in queue and a post blocked by the platform, you are already flying blind.
At Mydrop, we see teams struggle most when they rely on tools that lack visibility into these intermediate states. That is why we built our system to surface warnings rather than hiding them.
Use the scorecard below to evaluate the tools in your current stack.
| Capability | Agency Impact | Red Flag |
|---|---|---|
| Status Visibility | Allows triage of failed posts before clients notice. | Only "Success" or "Failure" states; no "Warning". |
| Proactive Alerts | Notifies the owner before a token expires. | Alerts only trigger after the post fails. |
| Constraint Checks | Catches aspect ratio/file size issues at creation. | No validation until the API returns an error. |
| Platform Granularity | Tells you exactly which platform failed and why. | Generic "API Error" messages. |
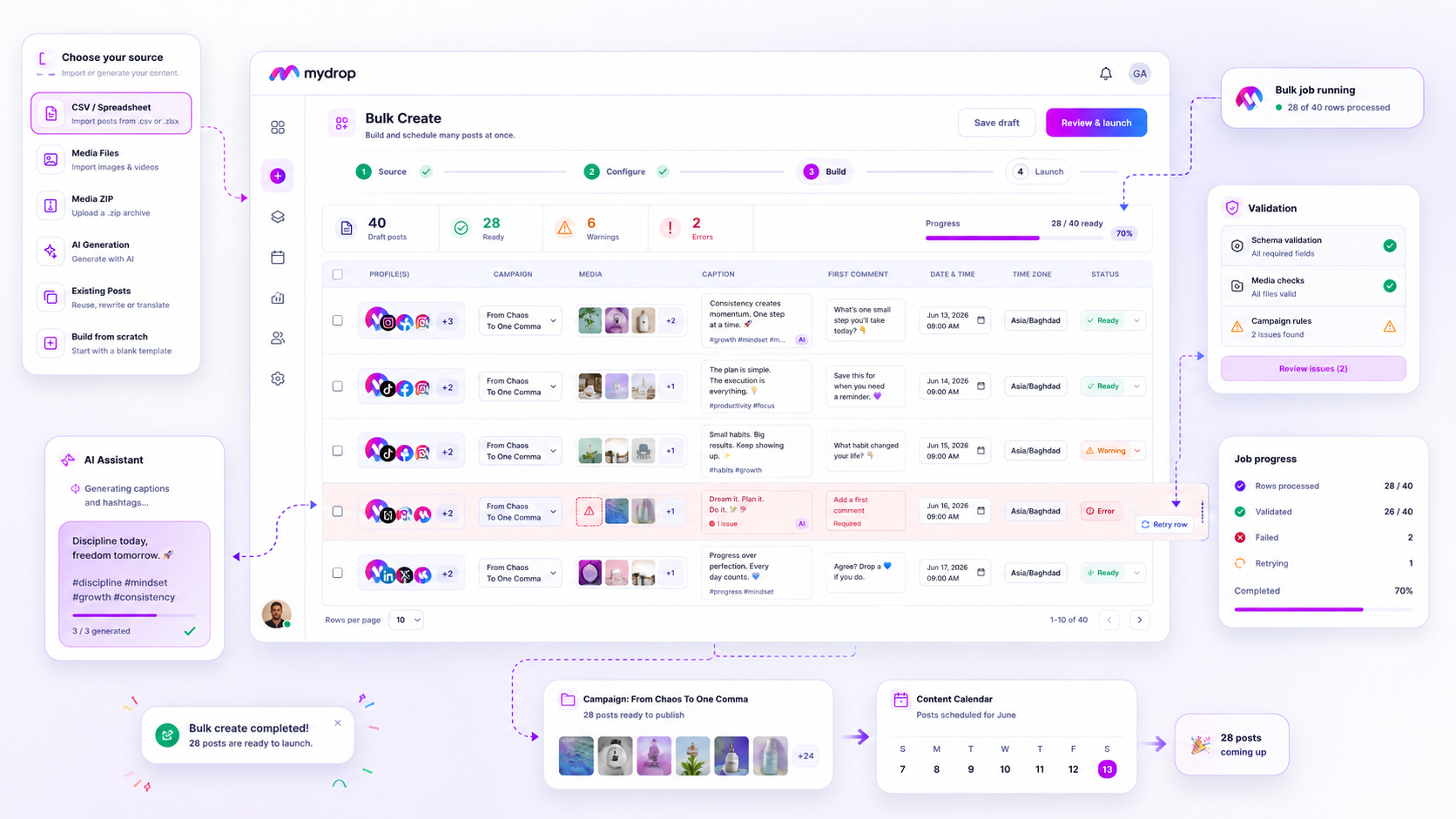
| Batch Management | Lets you bulk-retry or re-order failed tasks. | Requires manual re-entry for every failure. |
A simple rule helps here. If your tool does not tell you why a failure happened in plain English, it is not helping you fix it. It is just logging the carnage. Look for software that assumes things will go wrong, rather than software that pretends the world of APIs is perfect.
Most teams do not have a content problem. They have a decision bottleneck. If your team spends more time verifying that posts went live than actually creating them, you need to change your infrastructure, not your process.
How Mydrop supports this workflow
At Mydrop, we built our publishing engine with the understanding that platform errors are not just technical glitches; they are operational bottlenecks. If your current tool treats a failure as a generic alert, it is failing your team. We wanted to make sure that when a platform hits a snag-whether it is a token drift issue on LinkedIn or an unexpected quota limit on TikTok-your team knows exactly what to do and why it happened.
We moved away from the "hope for the best" publishing model. Instead, every post managed through Mydrop is tracked against its target platform’s requirements. Our status monitoring system differentiates between a post that is simply waiting in the queue, one that has encountered a recoverable warning, and one that has genuinely failed due to an external restriction.
Decision check: Never assume a pending post is a healthy post. If you do not know the state, you do not have control.
When a post enters a warning state, Mydrop triggers an automated email notification, ensuring your team is not left checking the dashboard for hours. This is not just about catching errors faster; it is about reducing the cognitive load on your social media managers. They should not have to monitor the system for failures; the system should notify them when action is required. By mapping platform-specific error codes into clear, actionable human language, we help you resolve issues immediately, rather than digging through support documentation for hours.
A simple shortlist checklist
Before you settle on a partner, run them through this scorecard. If they cannot answer these questions with confidence, your team will continue to scramble.
| Criterion | What to look for | Why this matters |
|---|---|---|
| Granular Statuses | Distinct states: waiting, warning, failed | Distinguishes between delay and actual errors. |
| Actionable Alerts | Specific error reporting (e.g., "Token expired," not "Publish failed") | Speeds up resolution time by knowing exactly what to fix. |
| Pre-flight Checks | Automatic validation of file sizes and aspect ratios | Prevents avoidable errors before they reach the platform. |
| Notification Logic | Configurable, automated alerts for failure states | Removes the need for manual monitoring. |
| API Limit Awareness | Ability to queue posts based on known rate limits | Keeps your publishing schedule stable. |
If you are comparing tools, use this as a quick filter. If a platform claims to be "enterprise-grade" but treats every error as a mystery box, move on.
Conclusion
Most teams do not have a content problem. They have a decision bottleneck.
When you are managing dozens of channels across multiple markets, your tools need to be as reliable as your team. The goal is not to create a perfect publishing world-that is impossible-but to create a world where you are not the last person to know when things go wrong.
The right publishing partner should act as your early warning system, not just a dispatch service. When you can trust that your tool will tell you precisely when and why a post failed, you move from reactive scrambling to proactive management. That change in mindset is what separates teams that are always fighting fires from teams that are actually building brands.
Pick a partner that values your time as much as you do. Ensure they give you the visibility, the specificity, and the notifications required to keep your publishing flow moving-even when the platforms throw an unexpected error your way.