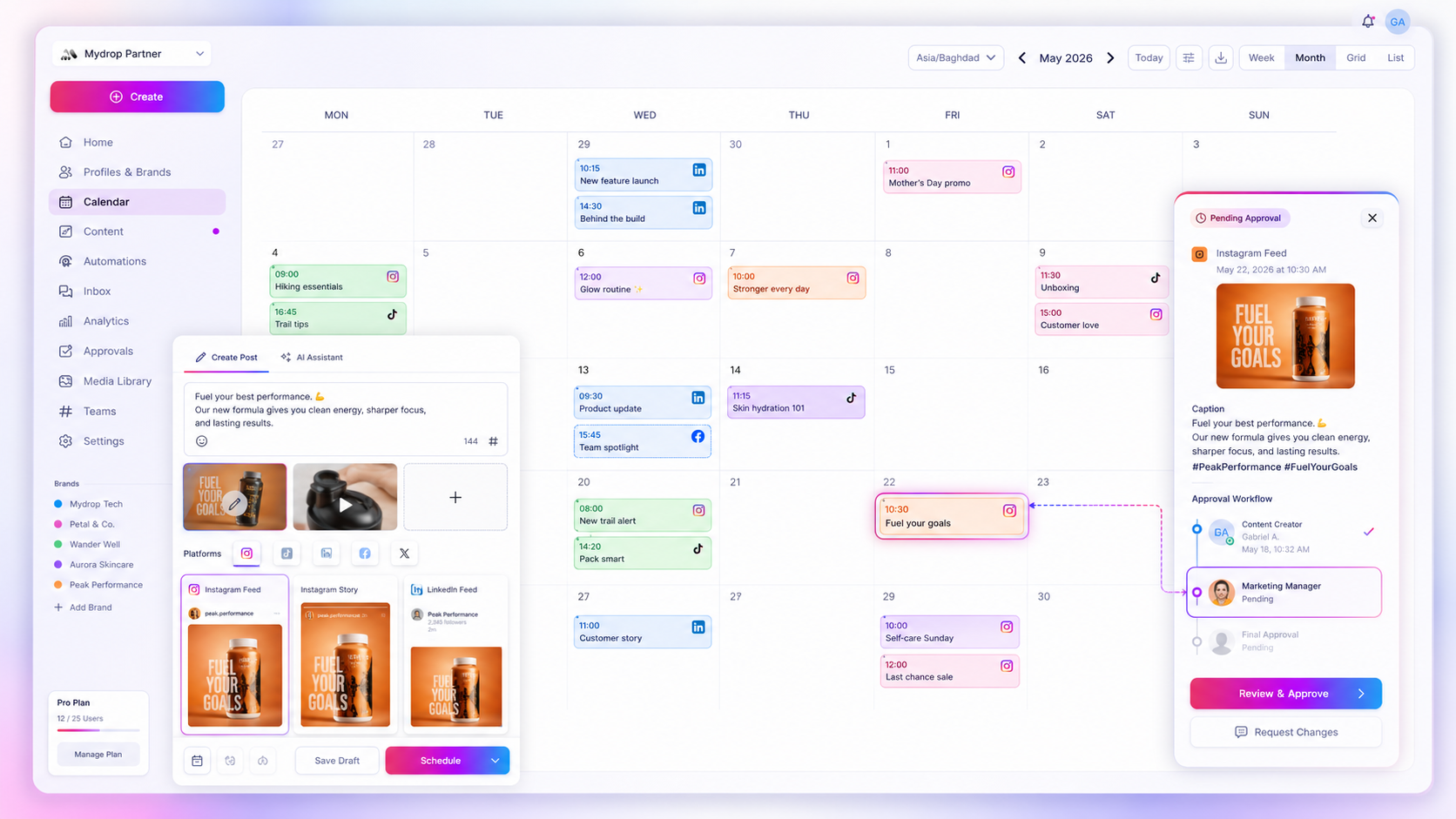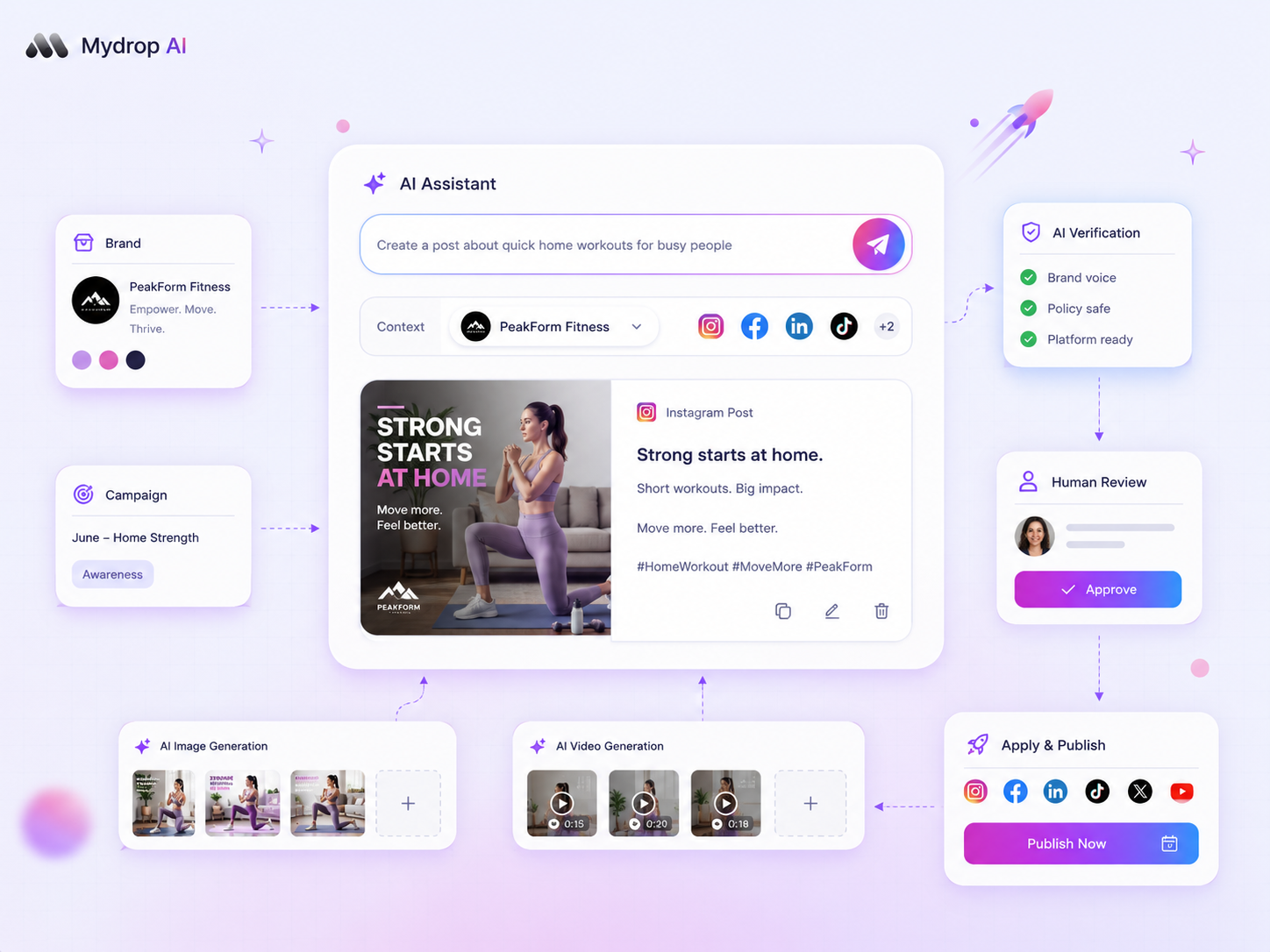
The most reliable way to handle AI-generated captions in a multi-brand environment is to stop treating them as final drafts and start treating them as raw materials that require a structured quality gate. If you are shipping raw output directly to your feeds, you aren't scaling your content; you are actively diluting the brand personality that your team has spent years building.
We get it. You are juggling three different brand voices, managing accounts across five platforms, and facing a content backlog that never seems to shrink. The pressure to push "publish" is constant, and the fear that a robotic, generic caption will sabotage a high-stakes campaign keeps you up at night. You are not alone, and frankly, the struggle is entirely normal. The danger isn't that the AI will write something "wrong"-the danger is that it will write something perfectly average, effectively turning a unique, high-end brand into a commodity voice.
The good news is that you don't have to choose between manual toil and algorithmic mediocrity. You just need a repeatable audit habit. At Mydrop, we see teams managing hundreds of profiles effectively not because they have more hours in the day, but because they treat the Composer AI panel as a starting line rather than a finish line.
The decision each metric should trigger

Once you accept that AI output is just a draft, you need a way to audit that draft without losing your mind. We recommend a simple, five-point assessment. This isn't about perfection; it is about protecting the "human spark" that keeps your audience engaged. When you or your leads review a generated caption, evaluate it against these five criteria. If the output fails even one of these checks, it needs a rewrite, not a minor tweak.
| Metric | Goal | Failure Trigger |
|---|---|---|
| Voice Fidelity | Sounds exactly like the brand. | Sounds like a generic "helpful assistant." |
| Context Precision | Uses specific brand/media cues. | Ignores provided attachments or brief. |
| Sentiment/Intent | Matches the campaign goal. | Tone is off (e.g., too casual for B2B). |
| Platform Nuance | Fits channel norms/formats. | Looks like a copy-paste from elsewhere. |
| Human Spark | Adds a unique, witty, or emotional hook. | Lacks any distinct human perspective. |
Operator rule: If you find yourself spending more than two minutes editing a generated caption to fix its tone, kill the draft and start over with a fresh, more specific prompt rather than trying to salvage the text.
This scorecard is designed to move your team from "total volume" metrics-which can be a vanity trap-to "pass-rate" metrics. If your team is consistently failing on Voice Fidelity, it is a signal that your saved prompts need a sharper injection of your brand guidelines. You are not just checking work; you are training your internal systems to work better for you. When you align your workflow to audit for these specific gaps, you reclaim control over your brand identity without having to write every character by hand.
The scorecard that keeps reporting useful

The biggest risk to your analytics dashboard isn't a bad caption; it's the noise created when generic AI output makes every brand in your portfolio sound like a carbon copy of the same assistant. When you report "volume of posts" as a success metric, you are essentially rewarding the machine for filling empty slots, regardless of whether those slots contain actual brand equity.
To fix this, we recommend moving away from vanity metrics and toward a Brand Alignment Scorecard. When you run an AI-generated caption through your internal review, assign a simple 1-to-3 score for each of these categories. If the total falls below a specific threshold, it triggers a mandatory manual rewrite.
| Metric | Score 1 (Fail) | Score 2 (Needs Edit) | Score 3 (Pass) |
|---|---|---|---|
| Voice Fidelity | Sounds robotic or generic | Misses specific brand nuances | Nails the established brand tone |
| Context Precision | Ignores provided media/brief | Misses one key campaign detail | Perfectly reflects assets and brief |
| Sentiment/Intent | Misaligns with campaign goal | Neutral/Generic tone | Clearly drives intended action |
| Platform Nuance | Clunky formatting for channel | Needs minor cleanup for native feel | Ready for platform deployment |
| Human Spark | Lacks emotional connection | Competent but forgettable | Includes that extra, authentic hook |
Decision check: Set your team's "Go-Live" threshold at 12 points. Anything scoring 11 or lower gets kicked back to the creator for a human polish or a more specific prompt refinement within the Mydrop AI Composer panel.
This isn't about being picky; it's about governance. When your team knows that every AI-assisted draft is being audited against these five pillars, the "robotic drift" stops, and the quality of your output stays consistent even as your volume scales.
What to stop measuring by default
Stop tracking "Total Posts Published" as your primary indicator of social team health. In a multi-brand environment, this metric is a dangerous siren song. It encourages teams to prioritize throughput-often relying on raw AI suggestions-at the expense of the very personality that drives your community growth.
Instead, shift your focus to the Content Pass-Rate. This is the percentage of AI-generated captions that pass your alignment scorecard on the first review without requiring a full rewrite.
- High Pass-Rate (>80%): Your prompt engineering is working. Your saved prompts in Mydrop are successfully capturing your brand voices, and the team knows how to feed the right context to the models.
- Low Pass-Rate (<50%): You have a coordination debt problem. This is a clear signal that your brand guidelines are not being translated into the specific, reusable prompts your team needs to succeed.
When you see a low pass-rate, don't blame the writers. Audit the inputs. Are they attaching the right brand files? Are they utilizing the media context? Often, we find that the failure happens because the "AI context" is too thin. Providing the model with a clear, structured brief-or a set of pre-approved brand examples-is usually the difference between a caption that gets deleted and one that gets the green light.
Treating AI output as a draft you can measure and iterate on, rather than a final product you blindly ship, is the only way to scale without losing your soul. Focus on the refinement loop, and the volume will take care of itself.
How to connect metrics to next actions
If your scorecard shows a cluster of 2s and 3s, don't just tell your team to "try harder." That is how you get burnout, not better captions. Instead, map those failures to specific prompt refinements. When you see a consistent dip in Voice Fidelity, your team likely needs a tighter saved prompt that explicitly defines the brand's banned words and preferred sentence structures.
If Context Precision is the culprit, you aren't feeding the AI enough substance. We often see teams treat AI like a mind reader, expecting a generic prompt to understand a specific new product launch. At Mydrop, we suggest attaching the actual product one-pager or recent campaign briefs to the Composer AI panel before generating. If the input is thin, the output will be fluffy.
Workflow check: Never treat a failing caption as a "writing issue." Treat it as an "instruction issue." If the AI misses the mark, edit the prompt, not just the text.
Here is how to triage your next steps based on the scorecard:
| Scorecard Finding | Likely Root Cause | Immediate Action |
|---|---|---|
| Low Voice Fidelity | Loose prompt definitions | Update brand saved prompt with specific stylistic examples |
| Low Context Precision | Missing asset data | Attach brand files or internal docs to the Composer AI panel |
| Low Platform Nuance | Generic prompt scope | Create platform-specific prompt templates for LinkedIn vs. TikTok |
| Low Human Spark | Over-reliance on automation | Lower the bulk-generation volume; force a human rewrite step |
The review cadence that makes the model stick
Most teams fail here because they view the "AI Audit" as a one-off project. To turn this into a habit, you need to weave it into your existing workflow. We recommend a simple bi-weekly sprint review where you pull the bottom-performing posts-not just by engagement, but by your new Brand Alignment Score.
Keep it fast. You don't need a three-hour meeting to know why a caption bombed. If you are using Mydrop to manage your workflow, pull up the AI usage history for a specific campaign, review three "failed" generations, and ask the team: "Did we give the AI enough context, or did we just ask for a miracle?"
- Tuesday Sprint Sync: Review the scorecard for the past 14 days.
- Identify Patterns: Are we consistently missing the mark on a specific platform?
- Refine Prompt: Update the relevant
saved promptin the AI panel. - Spot Check: Run a new test generation and score it immediately.
By making this a standing item, you shift the conversation from "why did the AI write this?" to "how do we sharpen our instructions for next time?" It moves you from passive frustration to active governance.
Conclusion
The goal isn't to reach a state where you never edit AI output. The goal is to reach a state where you are editing for nuance and "spark" rather than fixing basic errors in tone or missing context. When you treat AI as a junior partner rather than a shortcut, the coordination debt starts to shrink.
Stop chasing the mirage of a "set it and forget it" content pipeline. Your brands are too valuable to be left to the defaults of a language model. Use the scorecard to bring some rigor to the process, trust your human intuition to add the final polish, and get back to the work that actually builds your reputation. After all, the best social strategy is still a human one-AI is just the engine that helps you get there faster.