Moving from manual social posting to automated scheduling isn't about saving a few hours of copy-pasting. It is about removing the human friction that creates compliance drift and inconsistent publishing as your brand footprint expands. When you treat social publishing as a manual craft, you are betting your brand reputation on the hope that someone hits the right button at the right time across fifty different time zones. That is not a strategy; that is a high-stakes gamble.
We know the temptation. There is a tangible comfort in the manual publish button. You see the preview, you sense the tone, and you feel in control. But as you scale, that personal touch turns into a bottleneck. When your team spends more time fighting platform interface quirks and chasing stakeholders for a final sign-off than they do on actual creative work, you have hit the wall. At Mydrop, we often see teams hit this ceiling where the sheer weight of coordination-the manual checks, the re-uploads, the constant monitoring-starts to actively cannibalize their ability to respond to trends.
The decision each metric should trigger

Most teams operate in the messy middle, where manual posting is just barely sustainable until it suddenly isn't. You need a way to spot the warning signs before the coordination debt becomes too expensive to clear. Use this scorecard to evaluate whether your current manual setup is actually a liability disguised as an operating habit.
| Indicator | Manual Trap (Low Scale) | Operational Risk (High Scale) | Decision Metric |
|---|---|---|---|
| Weekly Output | < 20 posts | > 50 posts | If you exceed 50, manual review is a failure point. |
| Profile Count | 1-2 brands | 5+ brands / global | Fragmentation makes manual posting physically impossible. |
| Error Handling | Fix on the fly | Repeatable system failure | If you spend > 15% of your week fixing posting errors, switch. |
| Approval Path | Verbal / Slack | Audit trail required | Manual lacks the governance for enterprise risk. |
| Timing Needs | Ad-hoc | Strict, time-zone bound | Real-time global publishing requires machine consistency. |
Operator rule: If your team spends more than 15% of their total weekly output budget on manual platform navigation or resolving post-publishing formatting issues, you have officially outgrown the manual model.
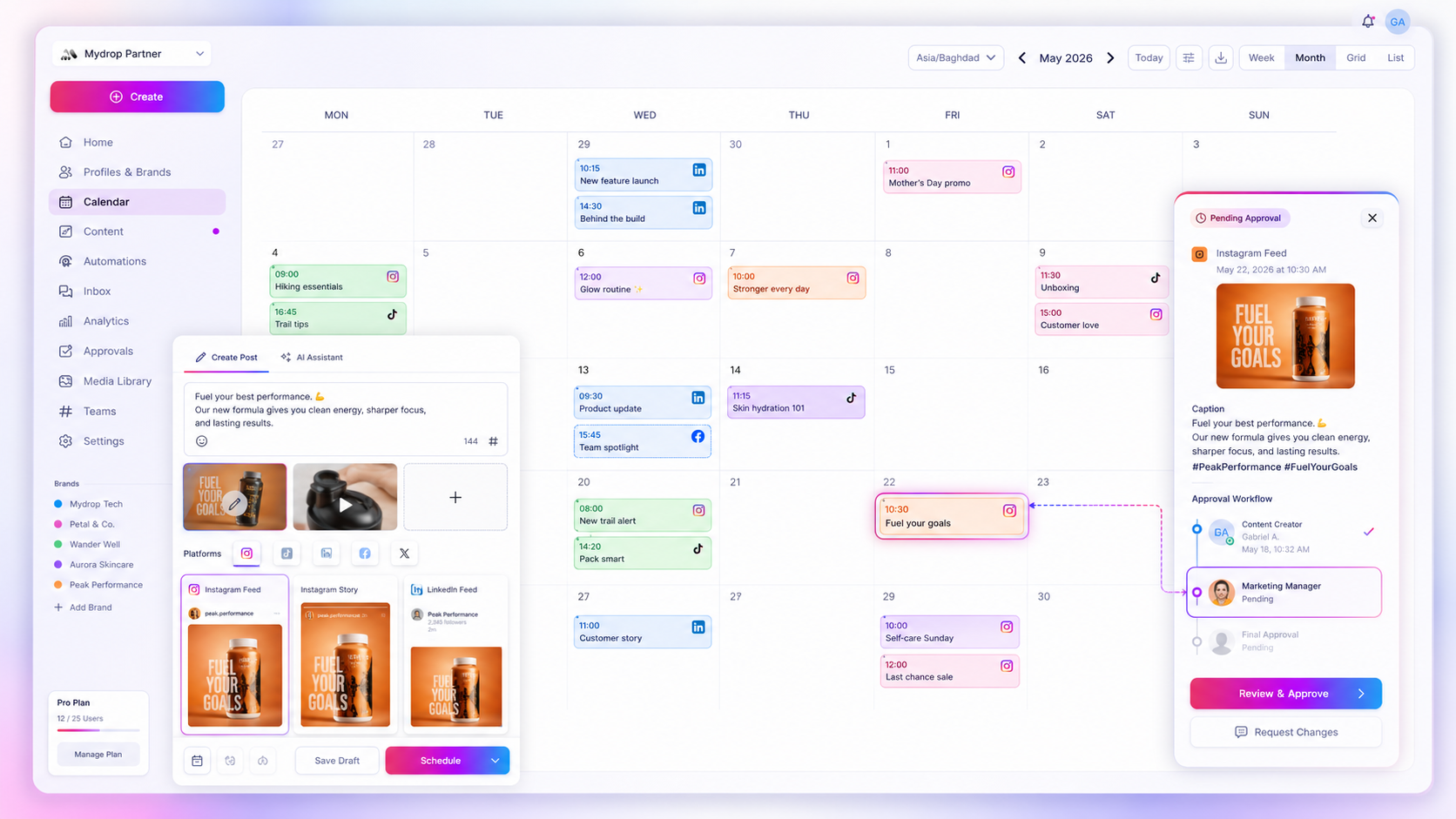
The transition isn't about giving up control; it is about choosing where to exert it. When you move to a centralized system, you stop being a digital librarian and start being a publisher. You want to spend your energy on the strategy, the creative, and the conversation, not on whether a video thumbnail uploaded correctly to a third platform at 3:00 a.m. When we help teams set up their calendar in Mydrop, the goal is to turn that high-stress, late-night publishing grind into a simple, automated coordination task.
Ultimately, your goal is to build an environment where the publishing happens reliably, on schedule, and without the anxiety of the 6:00 p.m. manual push. If the process requires you to be physically present at a computer to "go live," you are not managing a brand-you are tethered to a queue.
The scorecard that keeps reporting useful

Stop judging your output by vanity metrics like "total posts per week" and start grading your operations on governance stability. When you manually handle everything, your reporting becomes a forensic exercise-you spend half your time explaining why a post went out late, why the wrong asset was attached, or why a first comment was missing.
Use this scorecard to turn your weekly retrospective into a diagnostic tool. Grade your current process on a scale of 1 to 5, where 1 is "wild west" and 5 is "enterprise-grade stability."
| Evaluation Metric | The Manual Trap (Low Score) | The Automated Standard (High Score) |
|---|---|---|
| Publishing Drift | Often late due to team availability | Always on time per scheduled job |
| Asset Consistency | High risk of wrong file versioning | Canonical assets enforced by state |
| Approval Trail | Missing or verbal-only confirmations | Immutable audit logs per post |
| Error Handling | Discovery via user reports | Real-time warnings sent to owners |
| Cross-Platform Sync | Manual multi-entry, high fatigue | Single-source dispatch to all APIs |
If your team is consistently scoring a 2 or below, you aren't just moving slowly; you are carrying operational liability. A low score means your team is tethered to the clock, forced to be present just to hit a button. At Mydrop, we see teams realize that the most expensive part of their week is the "active wait"-that period where someone sits at a desk specifically to trigger a publication that could have been handled by the system three days prior.
What to stop measuring by default
The fastest way to kill a professional marketing team is to obsess over metrics that reward chaos. If you are currently tracking how many hours people spend "managing" posts, you are measuring the wrong side of the ledger. You should be measuring the delta between planned intent and actual execution.
Stop treating these as KPIs for a healthy team:
- Manual Touch-Points: High counts here don't show dedication; they show a lack of confidence in your workflow. If a post requires five people to verify it before it goes live, you don't have a content strategy-you have a meeting addiction.
- Response Latency: If you track how fast someone can manually reply to a platform-specific glitch, you are ignoring the root cause. A stable system should have already validated the media spec, the character count, and the user permissions before the job even reached the platform API.
- "Urgency" Premium: Some teams brag about how many posts they "saved" by manually jumping in at the last second. In a mature model, that isn't a save; it is a symptom of a process that failed to catch a problem earlier in the lifecycle.
Decision check: If a campaign requires "all hands on deck" just to hit publish, your setup is fragile. True scale is when the team is asleep, and the system is reliably handling the load because it already validated every piece of media against platform constraints.
When you shift from manual hand-off to a centralized schedule, the goal is to make the act of publishing invisible. You want to reach a state where you are only notified if something actually breaks. If you spend your morning reviewing logs of successful posts, you are doing work the machine should be doing for you. Reserve your focus for the content that isn't working or the strategy that needs a pivot, and let the boring, repetitive mechanics of the publishing queue run in the background without your intervention.
How to connect metrics to next actions
Stop judging your output by vanity counts like total posts per week and start grading your operations on governance stability. When you handle everything manually, your reporting becomes a forensic exercise where you spend half your time explaining why a post went live late or why a regional team missed the brand guidelines entirely.
Instead, connect your tracking to specific operational levers. If your error rate climbs, your next action is not a team meeting; it is a platform restriction check.
| Metric to Track | What it Actually Signals | Trigger for Change |
|---|---|---|
| Publishing Latency | The time delta between approval and go-live. | > 2 hours? Automate the dispatch. |
| Governance Drift | Count of posts requiring post-facto corrections. | > 5%? Centralize your asset library. |
| Capacity Ceiling | Weekly hours spent on copy-paste and upload. | > 15% of total time? Switch to a scheduler. |
| API/Provider Errors | Rate of platform-specific format rejections. | Any repeatable error? Build a format-check gate. |
At Mydrop, we see teams use the Calendar view to visualize their entire output rhythm; it turns a high-stress scramble into a predictable coordination task. By anchoring your metrics to these specific failure points, you shift the conversation from "we need more bodies" to "we need tighter systems."
The review cadence that makes the model stick
Most teams fail because they attempt to move from manual to automated in one big, terrifying jump. You do not need to rewrite your entire workflow overnight. Start by moving your lowest-risk brand profile into a scheduled environment for a single week.
Use this four-step transition to prove the model works before you scale:
- The Audit Week: Continue manual posting, but log every "Oops" moment-the typo you caught late, the platform-specific resolution fail, or the time zone mix-up.
- The Pilot Sync: Move one channel to a scheduled queue. Use the Mydrop post composer to set the date and time, and treat the scheduled event as the "source of truth" for the team.
- The Buffer Review: During the first week of scheduling, review the queue 24 hours before the intended go-live. If you feel the urge to "fix" it right before the timer hits zero, you have not built enough trust in your automated workflow yet.
- The Release: Remove the manual oversight for that channel. Shift your team's energy from "hitting the button" to "reviewing the engagement data."
Workflow check: If a platform post requires a thumbnail or first-comment addition, verify it in the tool settings immediately after initial scheduling. Do not assume the system handles manual quirks you have been doing by habit.
Conclusion
The messy middle of social media management is rarely about a lack of creative energy. It is about a lack of operational distance. When you are the one responsible for the final click, you lose the ability to see the broader content rhythm.
Transitioning away from manual posting is not about offloading work; it is about reclaiming the headspace to actually look at what you are publishing. The moment you stop worrying about whether a post will go live on time is the moment you can start worrying about whether it is actually resonating with your audience.
Stop being the human proxy for a server's job. Your brand deserves a strategy that runs itself, and your team deserves to spend their hours on growth, not manual maintenance.