
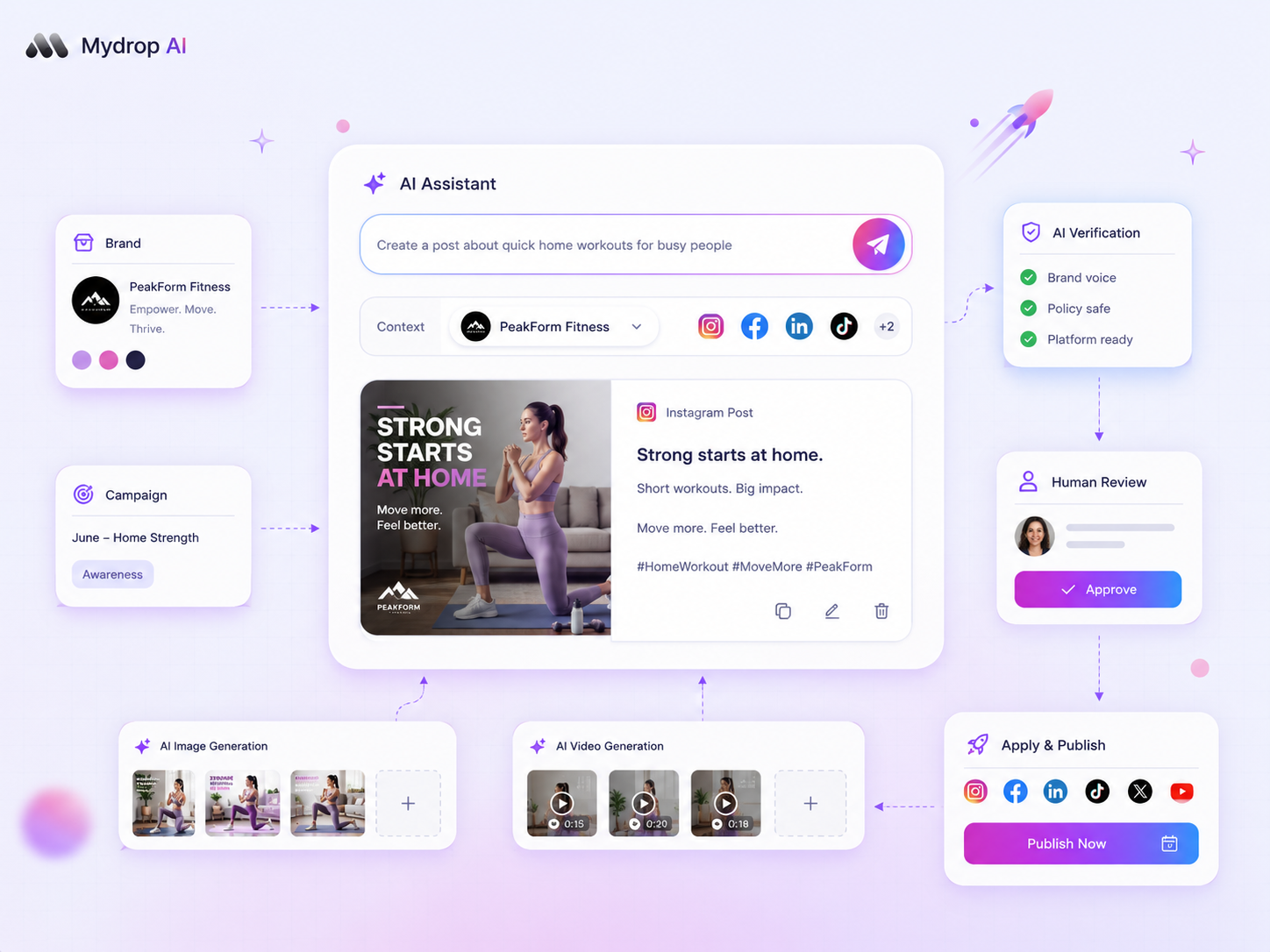
Deciding whether to trust AI with your social media captions comes down to one rule: If the model does not understand the why behind your post, you have no way of knowing if the output is ready for your audience. The quality of the draft is rarely about the AI's vocabulary; it is about how clearly you have fed it your brand voice, specific media context, and campaign goals. When you skip that setup, you are rolling the dice with your brand reputation every time you hit post.
We have all felt that sinking sensation-the queue is overflowing, the team is burned out, and an automated caption lands in the review stage sounding like a hollow, corporate echo. It is tempting to treat these tools as a magic button to clear your backlog, but in reality, that is how "creative atrophy" sets in. When your team stops auditing drafts, the brand starts to drift.
At Mydrop, we see this across hundreds of teams managing diverse brand portfolios. The ones who succeed do not treat AI as an autonomous writer; they treat it as an accelerator for their own intent. They use the AI to handle the heavy lifting of generative efficiency, but they keep a firm hand on the nuance to ensure every post feels human.
The decision each metric should trigger

To stop guessing if a caption is "good enough," you need a standard way to score your drafts before they ever reach a stakeholder. Think of this as your internal triage for the content calendar.
| Metric | Focus | High Trust (Automate) | Low Trust (Rewrite) |
|---|---|---|---|
| Brand Voice | Tone and vocabulary alignment. | Matches established style guide. | Sounds generic or "AI-robotic." |
| Accuracy | Factual precision and context. | References specific offer/data. | Hallucinates or misses the point. |
| Engagement Intent | Strategic hook and relevance. | Ties directly to visual hook. | Ignores the media attached. |
Operator rule: If a draft scores low on any of these, do not try to fix the caption-fix the prompt or the input context. Editing a bad AI draft is almost always slower than regenerating it with better guardrails.
When you are working through your queue, this scorecard turns a subjective "this feels off" conversation into a clear operational directive. If the brand voice is shaky, update your saved prompts to lock in your tone. If the engagement intent is weak, you are likely failing to use media extraction or attachments to give the model concrete visual data to reference. A simple calibration here saves hours of back-and-forth later in the approval loop.
The scorecard that keeps reporting useful

The most dangerous assumption teams make is that if a caption "sounds fine," it is ready to ship. That is how you end up with hundreds of posts that perform identically-flat, safe, and utterly forgettable. When you are managing dozens of profiles, you do not have time to stress over every semicolon. You need a way to move through your queue without sacrificing the brand.
To solve this, we use a simple Readiness Scorecard. When you pull an AI-generated draft in the Mydrop composer, do not just read it; grade it against these three benchmarks. If it does not hit a baseline score, it gets kicked back for a rewrite or a better prompt.
| Metric | Focus | When to Automate | When to Rewrite |
|---|---|---|---|
| Brand Voice | Tone consistency | Matches your style guide perfectly. | Sounds generic or uses buzzwords you avoid. |
| Context | Media & Data accuracy | Mentions specific details from the attachment. | Makes up features or misses the visual cue. |
| Engagement | The "Hook" | Contains a clear, actionable prompt. | Uses a tired, passive question like "What do you think?". |
This scorecard shifts the burden from "guessing" to "verifying." If the draft fails on Context, for example, you know the issue isn't the AI model-it is the lack of specific AI Attachments or brand-context files provided to the composer panel. You fix the input, you get a better output. It is that simple.
Decision check: If a caption requires more than two minutes of manual editing, the prompt is broken. Stop editing the text and start fixing your saved prompt.
What to stop measuring by default
Teams often fall into a trap of tracking the wrong vanity metrics when assessing their output. We see it across the board: managers obsession over "word count efficiency" or "time-to-first-draft." Those numbers are seductive because they are easy to pull, but they are hollow. Saving four minutes on a caption doesn't matter if your audience stops clicking.
Stop measuring how many drafts your team generates per hour. It creates the wrong incentive-it rewards volume over strategy. Instead, start measuring your Human Intervention Rate. This is the percentage of AI drafts that reach the final queue without significant changes.
If your team is touching 90% of your AI drafts, you do not have an efficiency problem; you have an expectation problem. Either your prompts are too loose, or you are asking the AI to handle tasks that require deep human nuance, like crisis communication or sensitive B2B partnership announcements.
The goal isn't to get the AI to write everything perfectly. The goal is to offload the heavy lifting so your best people have the brain space to focus on the 20% of content that actually moves the needle for your brand. When you stop chasing the efficiency mirage, you can finally start building an operating habit that prioritizes quality. Most teams don't have a content problem; they have a decision bottleneck. You are here to clear the path, not to manage the sheer volume of text.
How to connect metrics to next actions
The numbers you track in your dashboard only matter if they trigger a specific move in your workflow. If your virality score comes back as "Low," don't just sigh and post it anyway. Treat that score as an internal signal to swap your strategy.
Here is your action mapping for AI-generated drafts:
| Score Range | Strategic Meaning | Recommended Next Action |
|---|---|---|
| 80-100 | High alignment | Run a quick compliance check, then schedule. |
| 50-79 | Needs human nuance | Inject a specific brand insight or personal story. |
| 0-49 | Context mismatch | Discard the draft and refresh your saved prompt. |
When a draft falls into that middle range, it usually means the AI has the technical details right-the hashtags are there, the tone is professional-but it missed the emotional hook. Instead of rewriting from scratch, head into the Mydrop AI panel. You can use AI Attachments to feed the model a specific image or product brief from your assets. Giving the model concrete visual context to reference often boosts that score by 20 points in seconds.
Workflow check: Never settle for a "good enough" draft when your media assets already contain the missing context. If the AI doesn't see what you see, it can't describe it.
The review cadence that makes the model stick
Most teams fail here because they treat AI auditing as a "one-off" task performed right before clicking publish. That is how you end up with erratic quality. Instead, bake a 15-minute weekly audit into your team's rhythm.
Pick a random sample of five AI-generated posts from the previous week. Check them against your scorecard. If they are trending toward the "Rewrite" side of your rubric, your saved prompts have likely become stale.
Your weekly audit checklist:
- Spot Check: Pull five AI-generated captions from last week.
- Compare: Did the tone match the platform? (B2B LinkedIn vs. quick-hit TikTok).
- Refine: Identify one common flaw-is it being too wordy? Too corporate?
- Update: Adjust your saved prompt in Mydrop to explicitly block that behavior.
At Mydrop, we see that the highest-performing teams don't just use AI to generate; they use it to iterate. Their saved prompts evolve just like their brand strategy. When you treat your prompt library as a living document, you stop fighting the technology and start directing it.
Conclusion
Trusting AI for your social media captions isn't about blind faith in an algorithm; it is about building a controlled environment where you know exactly when to step in. Your goal is not to eliminate human oversight, but to sharpen it.
By standardizing your scorecard, linking scores to clear actions, and auditing your prompts weekly, you stop viewing AI as a wild card. It becomes a reliable member of your creative operations. You have enough to manage-from multi-brand compliance to shrinking lead times-without worrying if your caption sounds hollow. Stop guessing, start scoring, and keep your brand voice where it belongs: firmly in your hands.

