A failed post isn't just a missed deadline. It is a data point. When your publishing volume scales across dozens of channels, the difference between a transient API timeout and a systemic configuration error is the difference between a minor annoyance and a total workflow breakdown.
We get it. You are managing hundreds of posts across a global footprint, and seeing a "warning" or "failed" state in your dashboard feels like a constant, low-level alarm. It is messy, unpredictable, and exhausting to explain to stakeholders why a post didn't go live at the height of a campaign. But if you treat every red flag as an equal emergency, you end up with alert fatigue, where your team ignores genuine systemic failures until they become brand-damaging bottlenecks.
Most teams do not have a technical problem. They have an operational clarity problem. You need to distinguish between the noise of the internet-brief spikes in platform instability-and the debt you are carrying in your own scheduling operations.
The decision each metric should trigger

A metric without an owner and a set of required actions is just noise. To move from reactive firefighting to a repeatable habit, categorize your failures based on the fixability-whether it is a quick manual intervention or a deeper structural repair.
Here is a simple way to map those failures to the right team response:
| Failure Category | Likely Root Cause | Recommended Action |
|---|---|---|
| Technical Transient | API rate limits, server blips | Ignore (Monitor for frequency) |
| Asset Mismatch | Incorrect aspect ratios, file size | Review content guidelines |
| Permission Debt | Expired tokens, missing roles | Re-authenticate profile |
| Governance Gap | Missing approval, logic loop | Audit team workflow |
Operator rule: If a failure requires a manual "publish now" action, it is a task. If the same error type happens more than three times in a week across a single platform, it is structural debt that requires a workflow audit.
When we look at this across thousands of posts at Mydrop, we see that most "failed" states occur because a platform API changed its requirements-like an X Premium subscription lapse or a new thumbnail constraint on a short-form video-and the team didn't update the underlying profile settings. If your team is manually clicking "retry" every single morning, you have already lost. The goal is to move your operators away from patching individual posts and toward auditing the settings that caused the failure in the first place.
The scorecard that keeps reporting useful

You need a way to filter the noise so you can find the genuine bottlenecks. Instead of treating every platform error like a fire drill, map them against a simple health rubric. This keeps your team focused on what actually matters-keeping the pipeline moving-rather than chasing down transient ghosts.
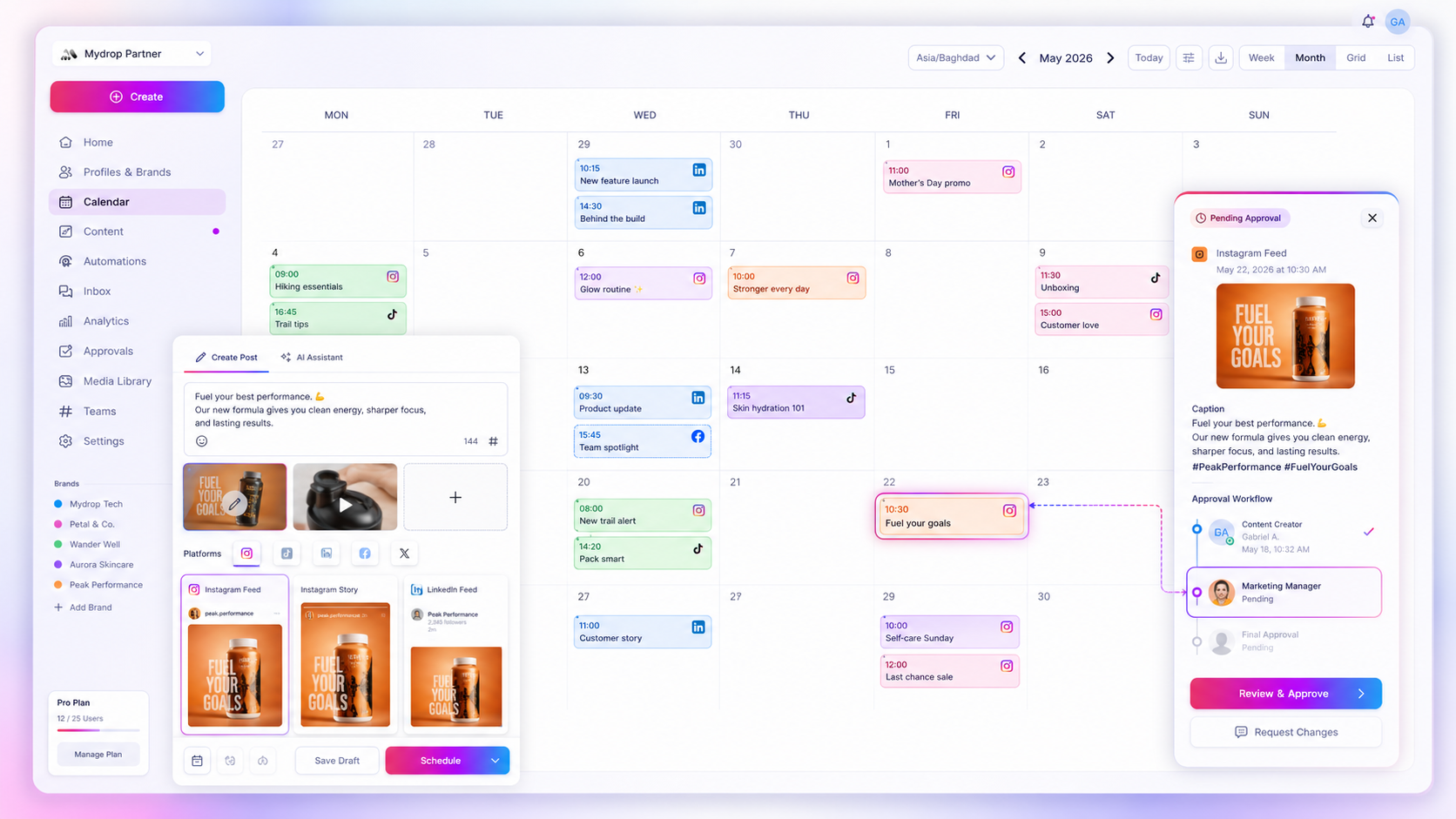
We recommend tracking your errors through a Publishing Health Scorecard. It turns those annoying dashboard red flags into a triage system. If you see a warning, you categorize it immediately, which tells you exactly how much effort you should invest in a fix.
| Error Category | Typical Trigger | Frequency Threshold | Response Action |
|---|---|---|---|
| Systemic Debt | Expired tokens, bad permissions, wrong media specs | > 3 times / week | Audit workflow; update credentials |
| Platform Noise | API timeouts, minor rate limits | > 10 times / month | Ignore (if self-correcting) |
| Operational Gap | Missing required fields, bad account link | Any instance | Immediate fix and process review |
Decision check: If a failure requires a manual "publish now" action, it is a task. If it happens more than three times in a week across the same platform, it is structural debt that requires an audit.
When you use a system like this, your team stops fearing the "warning" state in Mydrop. Instead of panicking, you see a report of "Systemic Debt" and know it is time to refresh your connection or re-train the team on specific platform requirements. It shifts the conversation from "Why is the system broken?" to "How do we fix this workflow?"
What to stop measuring by default
The biggest mistake we see is teams measuring metrics that trigger zero action. If your report includes a list of every single 404 or transient retry that resolved itself without intervention, you are just building a spreadsheet crime scene. It clutters your view, lowers morale, and buries the actual technical debt you need to address.
Stop tracking these if you aren't ready to act:
- Transient 404s or retries: If the system successfully publishes on the second attempt, let it go. You don't need a log for that.
- One-off platform glitches: An Instagram API hiccup that lasts six minutes and never happens again is not a trend. Do not let it haunt your monthly report.
- "Pending" states: If a post is simply waiting for its scheduled time in the Cloud Scheduler, it isn't an error. It’s just working.
Focus your energy on high-impact failures. If an X post fails because your Premium status lapsed, or your YouTube video hangs because the category field wasn't mapped, that is actionable data. That is where you find the coordination debt that actually kills your publishing velocity. Most teams do not have a content problem; they have a decision bottleneck. Once you strip away the noise, the path to a cleaner, more predictable publishing cycle usually reveals itself.
How to connect metrics to next actions
Once you have your scorecard in place, the real work is mapping those red flags to a specific, repeatable action. If a failure remains a "fire drill" handled by whoever happens to be online, you are just masking the symptoms of deeper coordination debt.
We recommend a simple Triage-to-Task flow for every warning or failure state surfacing in your dashboard.
- Categorize (The Source): Is this a Platform/API issue (e.g., token expiry, rate limits), a Workflow mismatch (e.g., aspect ratio violation for a Reel), or a Technical error (e.g., scheduled job timing out)?
- Assign (The Owner): Never leave a failure unassigned. API issues usually go to the lead operator; asset mismatches go to the creative lead; permission issues go to the brand account manager.
- Resolve & Document: If you fix it, document the why. Was the X Premium subscription actually expired, or was the API just being temperamental?
- Close the Loop: If it happens three times, stop fixing and start auditing the process.
Workflow check: If a failure requires a manual "publish now" action, it is a task. If it happens more than three times in a week across the same platform, it is structural debt that requires a workflow audit.
At Mydrop, we see teams often try to solve platform errors by just "publishing harder," which usually creates more API collisions. Instead, use the Status and Notification state tracking to pause the pipeline for that specific profile until the root cause-like an expired token-is cleared. Do not let the machine keep trying to force a square peg into a round API hole.
The review cadence that makes the model stick
You cannot audit your way to success if your team is only looking at these numbers once a quarter. By the time a monthly report comes out, the "transient" issues are already buried, and the systemic ones have likely cost you weeks of engagement.
Build a Weekly Publishing Debt Review into your operating rhythm. It does not have to be a long meeting. 15 minutes on a Friday afternoon is usually enough to look at the week's scorecard and spot the patterns that are actually slowing you down.
| Role | Responsibility | Frequency |
|---|---|---|
| Operator | Clear manual tasks, tag failure reasons, flag repeat errors | Daily |
| Lead Manager | Review Scorecard trends, audit recurring platform debt | Weekly |
| Strategy Lead | Reallocate budget/resources based on platform stability | Monthly |
Use this time to specifically ask: "Did our failure rate on Instagram Reels climb because the platform changed, or because we stopped checking our file specs?" Most of the time, the answer is the latter.
Conclusion
At the end of the day, social publishing failure rates are the most honest metric your team has. They tell you exactly where your process is brittle, where your team is overextended, and where your platform connections are starting to fray.
Stop viewing every red error icon as a personal failure or a technical mystery. Instead, treat them as the diagnostic signals they are. When you stop chasing every single fire and start auditing the systemic debt behind them, you stop being a digital firefighter and start being a social architect.
The goal isn't a perfect record-it's a predictable, resilient, and repeatable pipeline. Once you have that, you can actually get back to the work that matters: the creative that connects with your audience.