
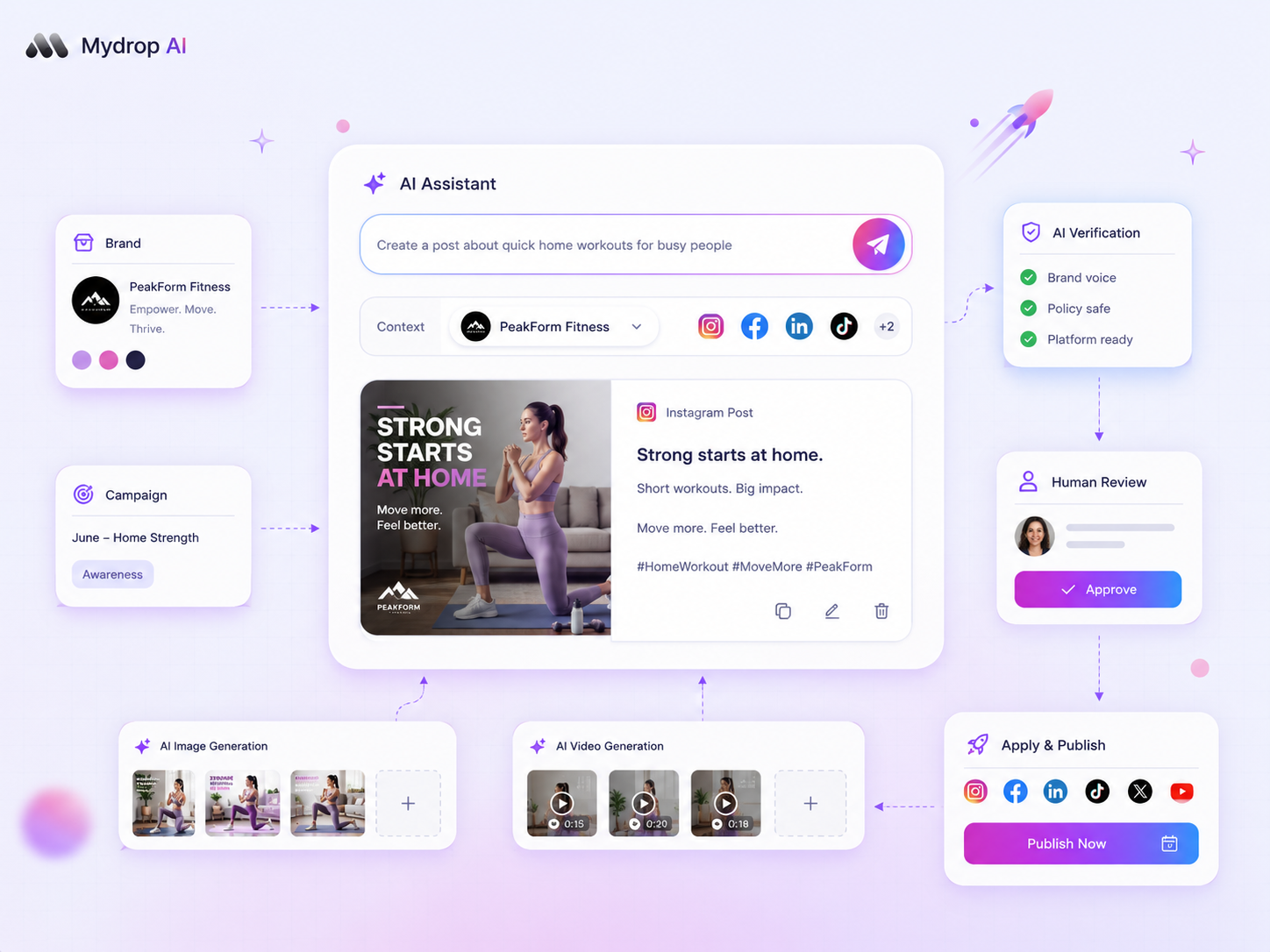
If your AI-generated social captions are consistently failing to drive engagement, you likely have a context failure, not a model failure. Most teams treat AI as a magic writing box, but without specific constraints-like brand voice, audience intent, or visual context-the output defaults to a generic middle ground that your audience has already learned to ignore. You aren't seeing low numbers because the AI is "bad"; you are seeing them because the AI is guessing, and it is guessing against a void of information.
We have all been there. You have a massive content calendar to fill, three stakeholders waiting for approvals, and a 6 p.m. publishing deadline. You flip on the AI, generate a few dozen captions, and hit schedule. But then, the metrics come back flat. That "engagement debt" isn't just a vanity metric-it is the sound of your brand disappearing into the scroll. The reality is that speed is not a substitute for strategy. If your inputs are thin, your engagement will be thinner.
What changed before the numbers moved

In our experience across thousands of enterprise workflows, the moment teams stop seeing "robotic" output is the exact moment they stop viewing the AI as a standalone writer and start treating it as an assistant that needs to be briefed. The AI is a high-speed engine, but it is effectively blind without a steering wheel.
Here is where the discrepancy usually hides:
- The "Blank Page" Trap: You are asking the model to write "a witty caption about X" without providing your specific brand guidelines or recent top-performing post examples.
- Missing Visual Clues: You are generating text without attaching the actual media, which means the AI has no idea if the post is a slick product video, a messy office BTS, or a high-end graphic.
- The Approval Vacuum: You are skipping the refinement stage because the AI already "gave you an answer," bypassing the critical human-in-the-loop audit that ensures the caption actually aligns with your campaign goals.
When you look at your recent underperforming posts, ask yourself if you gave the model the same brief you would give a junior copywriter on their first day. If you didn't, the AI didn't fail you-you skipped the instruction phase.
At Mydrop, we see the most successful teams using the Context-to-Engagement Scorecard below to audit why their copy feels stale. If you find yourself consistently in the lower-left quadrant, it is time to change your workflow before you generate another batch.
| Context Depth | Engagement Delta | Diagnostic Outcome |
|---|---|---|
| High (Prompted, Media-Linked, Brand-Aware) | High | Scaling Opportunity: Maintain this workflow. |
| High (Prompted, Media-Linked, Brand-Aware) | Low | Creative Mismatch: The copy is relevant, but the hook is weak. |
| Low (Generic "Write me a caption") | High | Luck: You hit the trend, but it is not repeatable. |
| Low (Generic "Write me a caption") | Low | Coordination Debt: You are flooding the feed with noise. |
Operator rule: If your AI input process takes less time than a Slack message, do not expect a high-performing post.
The fix isn't to work harder; it is to build a "context library"-a set of saved prompts and brand context files-that you can drag into the Composer AI panel for every new post. By grounding the AI in your specific assets, you stop the guessing game and start managing a real, repeatable operation.
The failure patterns to check first

When your AI-generated captions fall flat, the issue is rarely the sophistication of the LLM. It is almost always a case of context starvation.
Think of your AI as a brilliant but incredibly literal intern. If you hand this intern a link to a blog post and say, "Write a post for LinkedIn," you will get a generic, beige summary every single time. The AI lacks the "insider" knowledge that your team carries-the tone shifts for different product lines, the specific cultural nuances of your target market, or even the fact that you just announced a partnership that should be mentioned in every caption this week.
Here is where the breakdown usually happens:
- Context Poverty: You are sending raw content to the model without providing the brand guidelines or specific campaign objectives.
- Prompt Drift: You are manually typing or iterating on prompts instead of using saved, tested prompt templates that enforce your brand voice.
- Visual Disconnect: You aren't giving the model access to the actual media or attachments. The AI is guessing what the photo shows rather than interpreting the visual story.
- Approval Neglect: You are treating the output as "done" instead of using a quality-check step-like a virality score-to validate the draft before it hits the production schedule.
Decision check: If your team is spending more time editing AI captions than they would writing them, stop the pipeline. You are training your team to accept low-quality work, which is the fastest way to lose brand voice consistency across hundreds of posts.
The proof that separates signal from noise
We often see teams treat "AI engagement" as a mystery. It is not. You can quantify your input failure by looking at the relationship between the context you provide and the actual engagement delta you see on your posts.
We use this Context-to-Engagement Scorecard to help our teams identify why a batch of content is underperforming before they lose a week of publishing time.
Context-to-Engagement Scorecard
| Quadrant | Input Strategy | Engagement Result | Diagnostic |
|---|---|---|---|
| 1. The Ghost | No context, generic prompt | Flatlining (low) | Your posts are invisible; AI has no unique hook. |
| 2. The Echo | Basic content, generic prompt | Stale (medium) | You are just summarizing; no brand perspective. |
| 3. The Expert | Brand guidelines, specific attachments | Meaningful (high) | You are providing enough context to be relevant. |
| 4. The Authority | Brand context + Media + Virality Score | Viral (highest) | The model is synthesizing your strategy, not just text. |
To use this, look at your last 10 posts. If most fall into Quadrant 1 or 2, your problem is a lack of input hygiene.
At Mydrop, we have found that the best AI output comes not from the most advanced model, but from the most granular brand context provided. When you use AI Attachments to feed the model specific files or brand documentation, or leverage Saved Prompts to lock in your voice across different teams, you move from "summarizing" to "strategizing."
The goal isn't to get the AI to write more; it is to get the AI to write specifically about the assets you are actually publishing. If you see a caption that feels like it could belong to any brand in your vertical, that is your signal to stop and audit your context inputs. You aren't fighting the algorithm; you are likely just giving the model too little to work with.
What to fix this week
If your current AI output feels like it is stuck on loop, you do not need a new model; you need a workflow audit. Start by tackling the easiest wins that clean up your "coordination debt" before you commit to another round of manual rewrites.
Here is your 5-point checklist to run through this week:
- Purge the Generic Prompts: Delete any "make this viral" saved prompts from your team library. Replace them with specific, role-based templates-like "You are a senior community manager for a luxury footwear brand, write in a concise, authoritative, and helpful tone for Instagram."
- Standardize Your Context Attachments: Pick three high-performing posts from last month. Open the Mydrop Composer AI panel and attach the original media. See what the model generates now versus the raw text output. If the result is tighter, make "attach assets" a non-negotiable step in your team SOP.
- Run a Virality Score Test: Before your next batch publish, pick five drafts and run them through the AI virality score. If the score is low, use the feedback to refine your hook before the final approval round.
- Define Your "Human-Only" Zones: Decide which parts of your content (like sensitive crisis comms or high-stakes brand launches) are strictly off-limits for AI generation. Save everyone the stress of last-minute edits by putting this in writing.
- Establish a "Prompt Owner": Assign one person on the team to be the "Prompt Librarian." They are responsible for updating saved prompts when brand voice guidelines shift, ensuring the entire team isn't working from stale instructions.
Workflow check: If a caption requires more than three minutes of manual rewriting, the prompt is broken. Fix the input, don't just suffer through the output.
When to stop diagnosing and change the workflow
At some point, you have to stop tweaking the prompt and look at the assembly line. We see teams spend weeks trying to "perfect" an AI prompt for a channel where the audience simply does not respond to that format. That is not a model failure; that is a strategic misalignment.
If you have audited your inputs, refreshed your brand context, and are still seeing flat engagement, it is time to pivot the workflow entirely.
| Signal | What it actually means | Your next move |
|---|---|---|
| High volume, low signal | You are over-indexing on frequency over quality. | Reduce post frequency by 30% and reallocate that time to manual review. |
| Consistent "on-brand" but ignored | Your content is safe, but boring. | Force the AI to use an "experimental" prompt template for one campaign as a test. |
| High approval friction | Your stakeholders do not trust the AI output. | Stop using AI for the caption draft; use it only for hashtag research or initial ideation. |
Sometimes, the best use of AI is to stop using it for the final product and start using it for the heavy lifting of organization. Let the model suggest the structure, categorize your drafts, or draft your internal reporting notes. If it is not driving external engagement, stop making it the face of your brand.
Conclusion
The goal of your social operation isn't to see how much content you can push out with a machine; it is to maintain a high-trust connection with your audience at scale. AI is a tool, not a strategist. When the captions stop working, look past the model and check the context you are feeding it.
We have found that the best AI output comes not from the most advanced model, but from the most granular brand context provided. Secure your brand voice, ground your sessions in real assets, and treat your prompt library like a living document. Your audience will notice the difference-and your team might just get their 6 p.m. back.

