
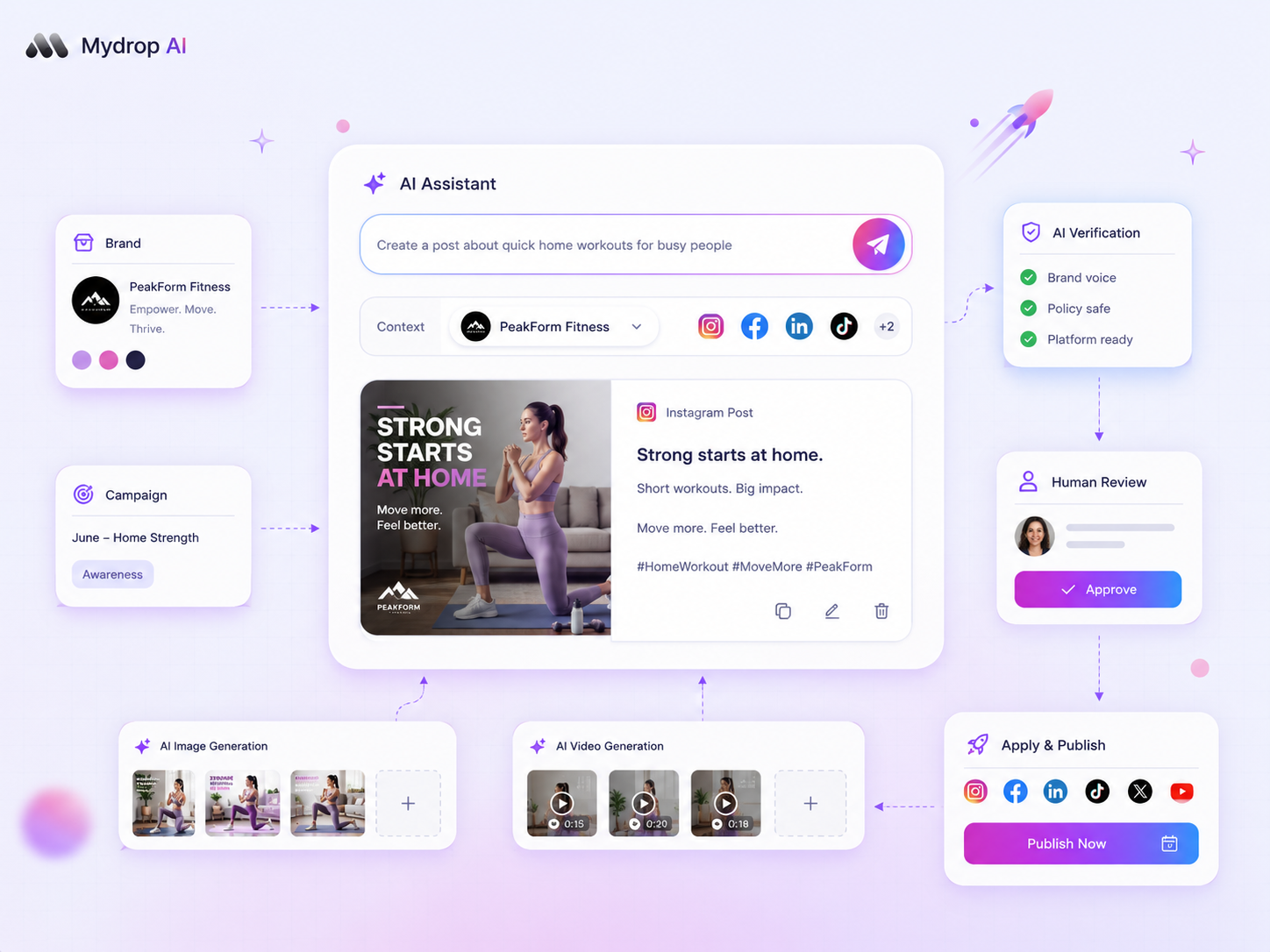
If your AI-generated captions are landing with a thud, stop blaming the LLM and start auditing your inputs. The difference between a high-performing post and a ghost-town performance is usually found in the few pixels of metadata or brand context you did not give the generator. We get it. You wanted AI to be the set-it-and-forget-it button for your content calendar, but instead, you are spending more time editing generic fluff than you would have spent writing the caption from scratch. This work is messy, and it is incredibly frustrating when the tool meant to drive efficiency becomes your biggest bottleneck.
The truth is that AI content failure is rarely a model error. It is context debt. You are likely handing the generator a prompt, but withholding the "brand physics" that make content actually resonate.
What changed before the numbers moved

Most teams that come to us after a rough week of performance have a consistent story. A few months ago, their manual process was slow but safe; they had a human rhythm, a shared understanding of the brand voice, and a clear sense of what performed in their specific markets. Then, they layered in AI to "scale up."
The workflow became frictionless, but disconnected.
In the rush to publish more, the human element-the "why" behind the post-got stripped away from the input data. When you stop feeding the generator the specific product intent, the current campaign style guide, or the recent sentiment from your last batch of posts, you are essentially asking the model to guess your brand’s personality from the entire internet. It will always default to the lowest common denominator of social media chatter.
Across thousands of posts we have monitored, we see the same transition point:
- The "Curation" Phase: You manually review every input. You tell the model the story. Results stay stable.
- The "Automation" Phase: You start using templates and bulk-generate without checking if the media matches the caption. Quality dips.
- The "Bottleneck" Phase: You stop trusting the AI because the output is consistently robotic. You are now manually rewriting 90% of the generated text, and your team is back to the same slow pace they had before.
If your engagement metrics are flat or dipping, you are likely stuck in that second phase. You have turned the handle on the machine, but you forgot to keep the funnel clear. The good news is that this is reversible. You do not need a more expensive model; you just need to re-introduce the context hooks that connect your brand reality to the output.
Operator rule: If you have to rewrite more than half of the AI output, stop automating the generation and start auditing the context inputs you provide to the composer.
The failure patterns to check first

When captions miss the mark, we often see teams jump straight to prompt engineering as if the LLM were a fickle creative director. In our experience, the problem isn't the model's imagination; it's a data gap. You are likely experiencing context starvation, where the AI is operating in a vacuum, divorced from your brand's current reality.
Here are the most common patterns we see across teams managing multiple brand profiles:
- The "Generic Voice" Trap: You are using a broad, company-wide prompt for a brand that actually has three distinct regional personas. If the AI doesn't know which persona is posting, it defaults to corporate beige.
- Context-Free Attachments: You attached a high-performing product video, but failed to pass the extracted metadata or transcript into your AI workflow. The model sees a generic video file, not the specific features that should be highlighted.
- Prompt Drift: Your saved prompts were written six months ago for a brand launch, but you are currently running a low-cost, high-volume performance campaign. The prompt is still optimizing for brand awareness while your goals have shifted to conversions.
- Virality Blindness: You are bypassing the feedback loop. Many teams treat AI as a "generate and publish" pipe, ignoring the scoring step that flags whether a caption is actually likely to resonate with the specific target audience of that channel.
The proof that separates signal from noise
Most teams do not have a content problem; they have a coordination debt problem. The best way to diagnose where your process is breaking is to map your current workflow against a simple performance scorecard. This isn't about blaming individuals; it's about seeing where the "human-in-the-loop" handoff is actually missing data.
Use this audit to determine if your captions are underperforming due to process or intent.
AI Caption Performance Audit
| Audit Point | Signal to Look For | Fix Strategy |
|---|---|---|
| Profile Alignment | Tone sounds "off" or inconsistent with regional standards. | Assign specific brand-voice profiles; restrict broad-model access. |
| Media Context | Captions ignore the specific product or offer shown in the image. | Enable attachment text extraction; verify media metadata is included. |
| Prompt Relevance | Captions sound repetitive or outdated. | Refresh your library of saved prompts to match current campaign goals. |
| Virality Score | High volume of low-engagement "fluff" captions. | Require a virality score check before the approval stage. |
| Human Review | Editors spend more time rewriting than approving. | Tighten the system prompt; include "do not use" constraints. |
Decision Rule: If your team scores below a 3 out of 5 on this audit, stop bulk-generating. You are currently creating coordination debt that your social media managers are forced to pay down during the final approval window.
At Mydrop, we see the most successful teams treat AI as a context-aware assistant, not an autonomous engine. When you feed the model your brand assets and specific campaign parameters-rather than just asking it to "write something for Instagram"-the output shifts from generic noise to actionable, brand-aligned copy.
What to fix this week
If you are currently staring at a week of scheduled content that feels "off," stop the presses and run this diagnostic check. You do not need to overhaul your entire strategy today; you just need to isolate the points of failure before the next round of posts goes live.
- Purge the Generic Prompts: If your
saved promptsare just generic requests like "Write a witty caption for this product photo," delete them. Replace them with specific instructions that include your current campaign goals and the exact product features being highlighted. - Audit Your Media Metadata: AI models are not mind readers. If you are attaching a video or image, ensure you are actually using the
attach fileorextract textcapability to feed the model the details of what is inside the file. If the model does not know there is a 30% discount mentioned in the graphic, it cannot talk about it. - Verify Profile Alignment: Are you accidentally using a "Corporate" voice prompt on an "Influencer-style" channel? Check that the profile selected in your
composer AI panelmatches the tone you need. - Run a Virality Score: Before you finalize, hit that
score viralitybutton. It is not magic, but it is a quick way to see if the AI thinks your caption is too wordy, too boring, or just plain misaligned with the visual content.
When to stop diagnosing and change the workflow
There is a point where tweaking the prompt becomes a waste of your senior staff's time. When you find your team spending more than 20 minutes manually "fixing" AI-generated text, the problem is no longer the prompt; it is your coordination debt.
In our experience across thousands of posts, teams that struggle with AI consistency are usually suffering from a lack of integrated brand context. If the AI does not have access to your brand colors, previous successful posts, or current campaign briefs, it will always default to generic filler.
| Symptom | Primary Workflow Failure | Immediate Fix |
|---|---|---|
| Captions are tone-deaf | No brand-aware context set |
Update brand settings and re-select profile |
| Features are missed | Ignoring media context |
Extract text/meta from attachments first |
| Output is robotic | Over-reliance on generic prompts | Shift to specific saved prompts per campaign |
| Approval cycles take >1hr | Using AI as a final draft | Force a human-in-the-loop review step |
If you are still stuck, stop automating the writing and start automating the context. At Mydrop, we find that the teams who see the highest lift are those that treat AI as a junior teammate who needs a very detailed, context-rich brief-not a ghostwriter who just "knows" what you want.
Conclusion
The reality of enterprise social media is that you are juggling too many voices to rely on guesswork. AI is a powerful force multiplier, but only if you provide the signal it needs to operate. Stop treating the generator like a vending machine and start treating it like a specialized tool that requires proper configuration. The next time a caption lands with a thud, don't just rewrite it; check your context, update your attachments, and tighten your workflow. Your engagement metrics will thank you.


