The secret to scaling social campaigns across dozens of markets and teams is to stop managing individual posts and start governing the production process itself. You are likely fighting a losing battle against coordination debt, where creative intent is slowly shredded by fragmented spreadsheets and manual re-entry errors. The fix is to treat your campaign creation as a repeatable, schema-driven operation rather than a series of one-off tasks. By moving to a structured intake model, you ensure that every asset and caption is validated against brand standards before it even touches your publishing calendar.
We have all been there: the launch is tomorrow, but the regional lead just pinged you with a typo in the main creative, and now you are stuck manually updating forty different scheduled entries. It is a soul-crushing way to spend an afternoon. When you shift your mindset from manual assembly to configuring a factory-style job, you finally regain control. This is not about removing human creativity, but about removing the mindless friction that makes enterprise-grade social work feel like a constant, high-stakes fire drill.
The decision each metric should trigger

When you standardize at the source, you stop asking "who forgot to tag this?" and start looking at high-level performance metrics that actually signal health. Use this decision matrix to determine if your campaign workflow is running efficiently or if your current process is creating invisible liabilities.
| Metric | Threshold/Indicator | Decision Trigger |
|---|---|---|
| Row Error Rate | > 5% failure in bulk upload | Audit source schema/formatting rules. |
| Retry Frequency | Frequent manual row intervention | Simplify input defaults; fix template mapping. |
| Job Setup Time | > 30 minutes for 50+ posts | Automate asset tagging; move to CSV-driven intake. |
| Validator Rejects | High variance across regions | Re-align regional teams to the core brand schema. |
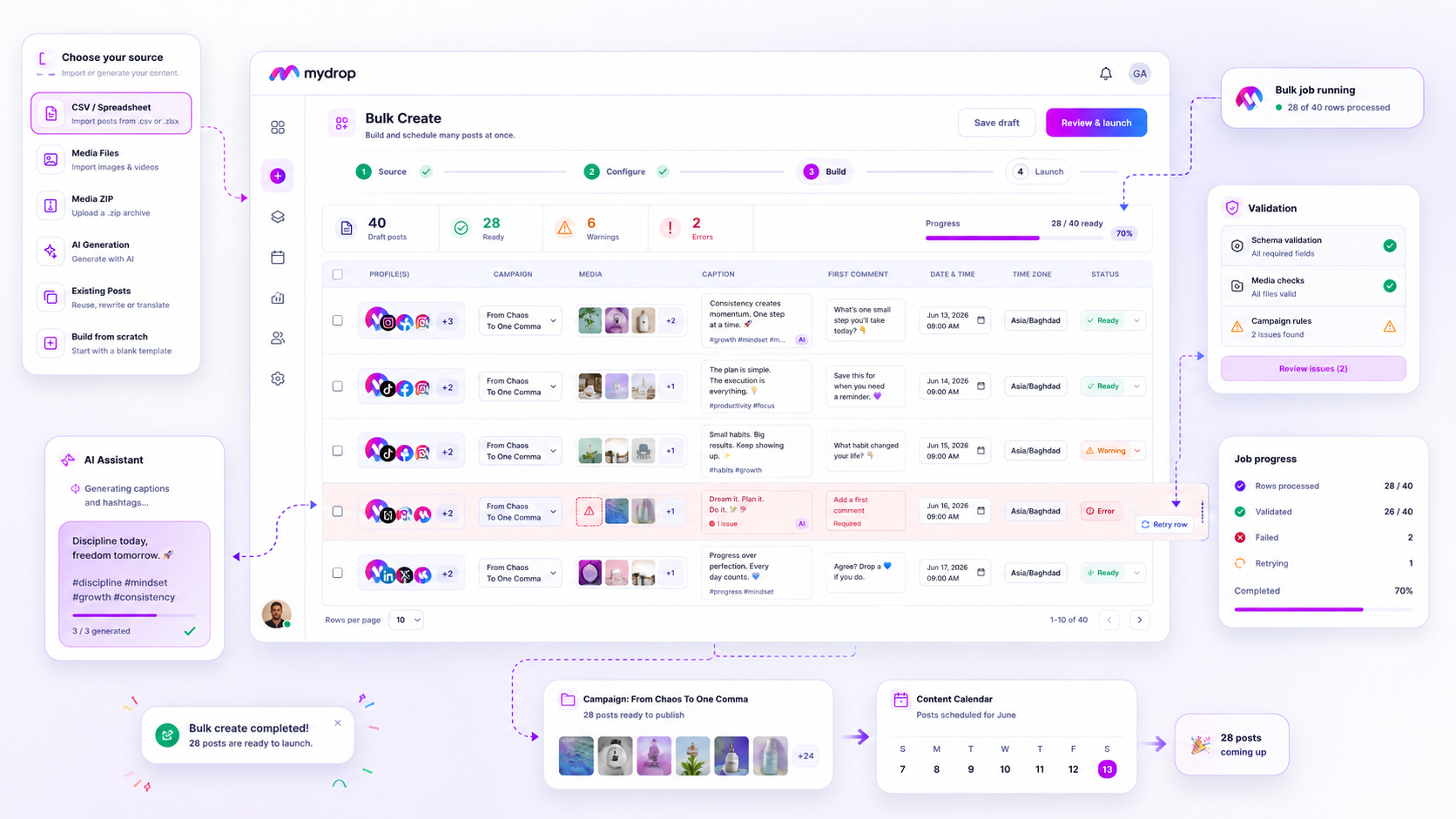
At Mydrop, we see teams struggle most when they try to fix errors downstream after a campaign has already hit the queue. It is vastly more efficient to use a bulk-creation engine that validates inputs at the point of ingestion. When your input source-whether that is a CSV or a media collection-requires structured data, you effectively force compliance through the process itself. If a row fails to meet your schema, it simply refuses to queue.
Operator rule: Never allow team members to "patch" individual posts once a bulk campaign has been launched. If the set is flawed, cancel the job, fix the source file, and re-launch. This preserves your audit trail and keeps the entire batch consistent.
This discipline prevents the "spreadsheet crime scene" where no one knows which version of a campaign is actually live. You aren't just saving time; you are creating a predictable output that allows you to treat your social presence as a stable, scalable asset.
The scorecard that keeps reporting useful

You should measure social performance by impact on production health, not just vanity metrics like total reach or aggregate clicks. If your reporting dashboard is full of data but silent on why a campaign missed its mark, you are looking at the wrong numbers. We have seen teams burn hours explaining "why" to stakeholders because they focused on outcomes while ignoring the health of the content engine itself.
A truly useful scorecard forces you to look at where the process is bleeding efficiency. If you cannot track the velocity of your feedback loop or the rejection rate of your drafts, you aren't managing a campaign; you are just watching a car crash in slow motion.
Here is an example scorecard to bring to your next status meeting. It focuses on the reality of your operations, not just the performance of your latest video.
| Metric | Threshold | Why it matters |
|---|---|---|
| Draft-to-Live Ratio | Target < 1.2 | High numbers signal churn and wasted creative hours. |
| Feedback Latency | < 4 hours | Long wait times on approvals kill campaign momentum. |
| Row Error Rate | < 2% | Tracks how often your bulk jobs hit formatting or schema snags. |
| First-Pass Success | > 90% | Measures how well your pre-validation catches errors before publishing. |
When a bulk job finishes in Mydrop, don't just check if the posts went live. Look at the row-level success rates. If you see recurring failures, you know exactly which team or channel needs a template update or clearer instructions, rather than sending a panicked Slack message to the entire department.
What to stop measuring by default
Stop tracking average response time across all channels as a single aggregate. It is a meaningless number that hides the specific teams that are actually struggling. If your EMEA team is hitting their targets but your APAC team is lagging by two days, an aggregate average hides the problem, leaving you to guess where to focus your training efforts.
Similarly, kill the total number of posts scheduled as a primary KPI. It incentivizes the wrong behavior: quantity over governance. Teams will happily dump hundreds of low-quality posts into the calendar just to satisfy a "volume goal," while your compliance and brand teams scramble to clean up the resulting mess.
Decision check: If a metric does not trigger a specific, actionable task for a human in the next 24 hours, stop reporting it.
Focus instead on the stability of your production environment. You want to know if your team has the tools to hit their targets without constant manual intervention. If your workflow relies on manual fixing, you are not scaling; you are just working harder. Shift your energy from reporting on past performance to validating the process that ensures future success. When you stop obsessing over aggregate reach and start governing the quality of your inputs, you finally gain the head-room to actually innovate.
How to connect metrics to next actions
Stop treating your dashboard as a historical trophy case. If a metric doesn't trigger a specific, binary decision, it is just noise. Most social leaders we speak to spend hours looking at "Engagement Rate" without ever asking if that number should change how they brief the creative team next week.
A metric only becomes useful when it moves you into a state of active production. If you see high saves but low shares on your tutorial content, the next action isn't to "post more." The next action is to update your campaign schema to prioritize high-value, saveable carousels over quick-hit video.
Decision rule: If your data can't force a change in your upcoming content calendar, stop tracking that metric until you have a workflow that acts on it.
The review cadence that makes the model stick
Coordination debt accumulates when you wait until the last minute to find out that a creative direction has drifted from the brand strategy. The most disciplined teams we work with replace the "big weekly status update" with a rolling, asynchronous review.
Instead of burning two hours on a Friday morning chasing approvals, use a mid-week audit to ensure the machine is still on track.
| Stage | Review Frequency | Primary Goal | Action Trigger |
|---|---|---|---|
| Strategy Audit | Bi-weekly | Align on core themes | Update source templates |
| Bulk Job Scan | Daily (10 min) | Catch format/link errors | Retry failed rows in bulk |
| Performance Review | Monthly | Adjust production mix | Shift budget/resource focus |
When you use a tool like Mydrop’s Bulk Create engine to process your posts, you get row-level visibility into every single asset. If a post fails, you don't hunt through a spreadsheet or ask a designer to check the file. You see the error, fix the row, and trigger a retry. This keeps the production moving while everyone else is still busy arguing about whether a post is "on brand."
Conclusion
The secret to scaling social operations isn't hiring more people to do more manual labor. It is changing how you think about the work itself. When you treat your content as a structured, validated set of data rather than a series of individual tasks, you stop being a bottleneck and start being an architect.
You can spend your time worrying about creative strategy and meaningful community interaction, or you can spend it manually fixing formatting errors at 6 p.m. because the latest batch of posts failed.
Most teams do not have a content problem. They have a decision bottleneck. Once you install a consistent, automated way to build, validate, and track your output, the quality-and the sanity of your team-tends to take care of itself. Stop building posts one by one. Start governing the system that creates them.